PCIe如何帮助构建ML加速器?
2022-01-13 12:18:44
EETOP
点击关注->创芯网公众号,后台告知EETOP论坛用户名,奖励200信元
机器学习 (ML),尤其是基于深度学习 (DL) 的解决方案,正在渗透到我们个人和商业生活的方方面面。基于机器学习的解决方案可以在农业、媒体和广告、医疗保健、国防、法律、金融、制造和电子商务中找到。就个人而言,当我们阅读推送新闻、播放我们的推荐音乐、在我们的网站购物以及当我们与Siri 交谈时,ML 会触及我们的生活。
由于机器学习技术在商业和消费者用例中的广泛使用,很明显,为ML 应用提供高性能和降低总运营成本的系统将对部署此类应用程序的客户非常有吸引力。因此,高效处理ML 工作负载的芯片市场快速增长。
对于数据中心等一些市场,这些芯片可以是离散的ML 加速器芯片。鉴于潜在市场,离散ML 加速器市场竞争激烈也就不足为奇了。在本文中,我们将概述离散ML 加速器芯片供应商如何利用PCIe 技术使他们的产品在竞争异常激烈的市场中脱颖而出。
利用 PCIe 制造满足客户需求的 ML 加速器芯片
除了为尽可能广泛的机器学习用例集提供每瓦每美元的最佳性能外,在竞争激烈的ML 加速器市场中,还有一些功能可以作为赌注。首先,加速器解决方案必须能够连接到尽可能多的来自不同供应商的计算芯片。选择广泛采用的芯片到芯片互连协议(例如PCI Express (PCIe))作为加速器/计算芯片互连解决方案将自动确保加速器可以连接到几乎所有可用的计算芯片。
其次,加速器必须易于使用Linux 和 Windows 等标准操作系统进行发现、编程和管理。使加速器成为 PCIe 设备可以自动使用为 PCIe 设备定义的枚举流来发现它,并使用标准操作系统使用通用的编程模型进行配置和管理。通常,供应商必须为其加速器产品提供设备驱动程序。为PCIe 设备开发驱动程序是众所周知的,并且有大量的开源代码和信息可供供应商用于驱动程序开发。这降低了供应商产品的开发成本和上市时间。
应用软件必须能够以最少的软件开发工作量和成本使用加速器。通过将加速器转变为 PCIe 设备,可以立即部署用于访问和使用 PCIe 设备的众所周知的稳健软件方法。
随着云计算的普及,很大一部分基于ML 的应用程序作为虚拟机实例或容器托管在云上。通过访问ML 推理或训练加速器,可以提高这些虚拟机或容器的性能。因此,如果可以将ML 加速器虚拟化,使其加速能力可供多个VM 或容器使用,那么它在市场上的吸引力就会提高。
设备虚拟化的行业标准是基于PCIe 技术的:SR-IOV。此外,由于提供的高性能,直接将 PCIe 设备功能分配给 VM 得到广泛支持和使用。因此,通过为其加速器实施PCIe 架构,供应商可以解决需要高性能虚拟化加速器的细分市场。
训练
在机器学习模型可以在生产中部署之前,它们必须经过训练。ML的训练过程,尤其是深度学习,涉及将大量训练样本输入到正在训练的模型中。
在大多数情况下,这些样本需要从存储系统或网络中获取或流式传输。因此,训练到可接受的预测或准确性水平的时间将受到 ML 加速器和存储系统或网络接口之间链路的带宽和延迟属性的影响。训练时间越短,加速器解决方案对客户来说就越好。
加速器可以通过使用PCIe 技术的点对点流量功能直接从存储设备或网络流式传输数据,从而潜在地缩短训练时间。以这种方式使用点对点功能可以通过避免在主机计算系统的内存中为训练样本来回调度来提高性能。
此外,大多数高性能存储节点和网络接口卡(NIC) 使用基于 PCIe 协议的链路连接到系统中的其他组件。因此,通过选择成为符合 PCIe 的设备,加速器可以启用与大多数存储和 NIC 的本地对等流量。
PCIe 架构的点对点功能在机器学习的推理和生成方面也很有用。例如,在自动驾驶中的对象检测等应用中,需要以尽可能低的延迟将恒定的摄像头输出流馈送到推理加速器。在这种情况下,点对点功能可用于以最小延迟将相机数据流式传输到推理加速器。
机器学习加速器芯片与计算芯片、存储卡、交换机和网卡之间的高带宽连接要求需要高数据速率的串行传输。随着数据速率的提高以及芯片之间的距离扩大或保持不变,需要先进的PCB 材料和/或范围扩展解决方案(例如重定时器)来保持在通道插入损耗预算范围内。
重定时器完全在 PCIe 规范中定义,可以支持广泛的复杂电路板设计和系统拓扑。因此,使加速器成为PCIe 设备使加速器供应商能够利用PCIe 技术生态系统在各种客户板设计和系统拓扑中实现必要的高数据速率串行传输。
复杂模型的多个加速器
自然语言处理等机器学习领域的领先优势正在转向像GPT-3(具有 1750 亿个参数)这样的极其庞大和复杂的模型。由于此类大型模型的参数存储要求和计算要求,使用这些模型的训练甚至预测或生成(例如,在语言翻译中)可能超出单个加速器芯片的计算和存储容量。
因此,当像 GPT-3 这样的大型模型是用例的首选时,一个具有多个加速器的系统就变得很有必要了。在这样的多加速器系统中,系统组件之间的互连需要提供高带宽、可扩展并且能够容纳连接到互连结构的异构节点。
PCIe 技术因其高带宽以及通过部署交换机进行扩展的能力而成为系统组件互连的绝佳选择。如前所述,无处不在的基于PCIe 的设备允许相同的结构具有NIC、存储设备和加速器。这允许有效的点对点通信,从而缩短训练时间、降低推理延迟或提高推理吞吐量。对于需要低延迟和高带宽的加速器间互连的多加速器用例,加速器供应商可以利用PCIe 规范的替代协议支持来创建自定义加速器间互连。
在设计加速器以训练 GPT-3 等大型模型或使用此类模型进行推理时要考虑的另一个重要方面是必须向加速器提供大量功率,以使其以最高性能水平处理这些模型。PCIe规范为系统提供了向加速卡提供大量电力的标准化方法。通过使用 PCIe 技术,加速器供应商可以安全地设计一个加速卡,该卡消耗 PCIe 架构标准允许的卡的最大值,而无需担心来自各种系统供应商的系统互操作性。
ML 解决方案的每美元性能部分取决于其功率效率。例如,推理加速器可能仅在新推理请求从计算SoC 传递到加速器时才使用其与计算SoC 的链接。在剩下的时间里,链路基本上是空闲的。除非链路具有低功耗空闲状态,否则它将通过保持在高性能活动状态而不必要地消耗功率。
为了获得最大效率,加速器与系统其余部分的链接的功耗与这些链接的利用率呈线性关系是很重要的。PCIe提供 L1 和L0p 等链路电源状态,以根据空闲和带宽使用情况调节链路的功耗。
此外,PCIe 规范具有设备空闲电源状态(D-states),标准操作系统可以利用这些状态通过在不需要时让加速器进入睡眠状态来降低系统功耗。PCIe技术还提供了控制加速器有功功耗的能力。因此,PCIe 规范使加速器能够对系统的整体电源效率做出积极贡献。
PCIe 和 RAS
对于 AI 加速器的数据中心部署,包括加速器在内的所有系统组件都需要可靠性、可用性和可维护性(RAS) 特性。此外,为了在实践中可用,此类RAS 功能必须符合标准操作系统和平台固件的要求。PCIe架构提供了一套丰富的操作系统友好的 RAS 功能,包括高级错误报告、热添加和移除 PCIe 设备的能力等。因此,选择基于 PCIe 的链路作为连接其他系统组件的方式有助于加速器产品满足数据中心市场的RAS需求。
PCIe 规范为AI 加速器供应商提供的一个重要优势是能够将相同的解决方案重新定位到几个不同的细分市场。这是通过利用PCIe 技术的两个特性来实现的:不同外形尺寸的可用性和PCIe 规范接口具有不同链路宽度的能力。这允许供应商根据细分市场所需的加速能力按比例扩展接口带宽、功耗和外形尺寸。
传输到加速器和从加速器传出的数据的机密性和完整性对于大多数客户来说都很重要。PCIe规范最近为 PCIe 链路上的数据传输引入了完整性保护和数据加密(IDE)。加速器供应商可以利用PCIe IDE 为数据提供端到端的机密性和完整性。
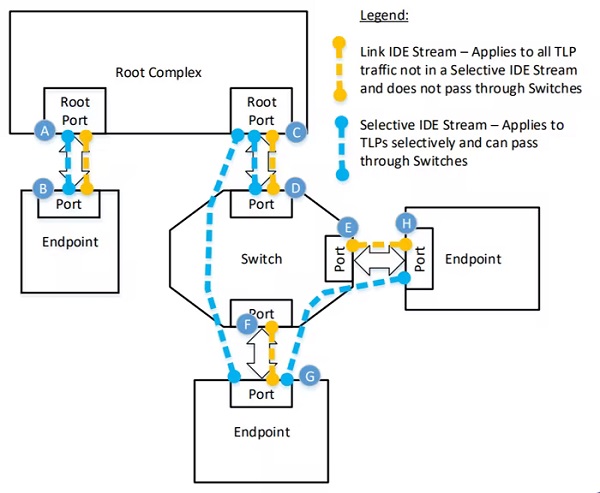
训练和推理工作流程都可以涉及计算SoC 中的 CPU 内核和以协作方式执行 ML 应用程序的加速器。这需要计算SoC 和加速器之间的高带宽、低延迟通信通道。基于PCIe 的链路非常适合此应用。通过利用PCIe 规范对自定义芯片到芯片通信协议的替代协议支持,甚至可以实现更低的延迟和更高的带宽效率。
由于 ML 加速器市场的竞争性质,缩短上市时间对于加速器供应商来说非常重要。由于丰富的生态系统提供了可用于快速芯片设计和验证的高质量PCIe IP,因此利用 PCIe 技术可以在这方面有所帮助。供应商可以轻松访问合规性测试服务,以确保他们的芯片能够连接到所有与PCIe 技术兼容的计算系统,并且他们可以访问大量PCIe 架构专家。
结论
如前所述,机器学习(尤其是深度学习)模型的规模和复杂性都在增长。为了在计算和内存容量方面跟上这一趋势,具有多个互连加速器芯片的系统将变得越来越必要。芯片到芯片的互连性能需要与计算和内存容量一起提高,以实现此类系统的真正性能潜力。
选择用于芯片到芯片互连的PCIe 技术有助于供应商利用每一代新一代PCIe 技术为市场带来的带宽增长。昨天PCIe6.0最终版正式发布,将是上一代PCIe 5.0 数据速率的两倍。
采用 PCIe 规范将使 ML 加速器供应商能够以更低的风险和更快的上市时间开发市场领先的加速器。它还提供了一条稳健的途径来满足扩展芯片到芯片互连带宽的工作负载需求。
https://www.electronicdesign.com/technologies/embedded-revolution/article/21213976/pcisig-how-pcie-specs-can-help-build-machinelearning-accelerators
关键词:
PCIe
PCIe6
ML
机器学习
深度学习
-

EETOP 官方微信
-

创芯大讲堂 在线教育
-

创芯老字号 半导体快讯
-
 1
1



















