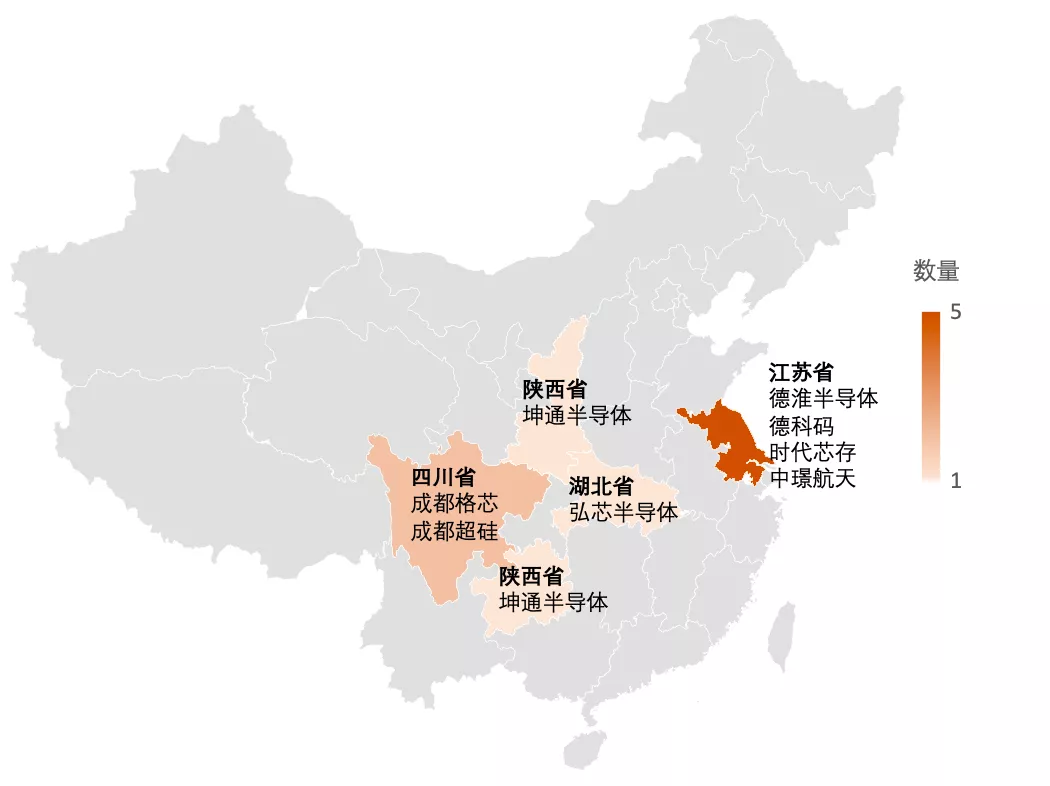
被腾讯看中的人工智能芯片--DTU 1.0 亮相Hot Chips
2021-08-31 12:46:30 EETOP中国的顶级超级计算机--包括神威太湖之光或强大的天河 2A--都采用了本土技术,从芯片到互连。而中国的社交媒体巨头,包括阿里巴巴和百度,已经在生产使用自研芯片的的设备,用于大规模的人工智能训练和推理。
作为BAT 之一的腾讯目前还没有推出自己的芯片。但值得注意的是,腾讯对总部位于上海的燧原科技进行了大量投资。
该公司很快将发布其第一代AI训练设备--DTU 1.0,该设备自2018年以来一直在开发中。在过去三年里,燧原科技已经筹集了近5亿美元的资金,由腾讯领头。
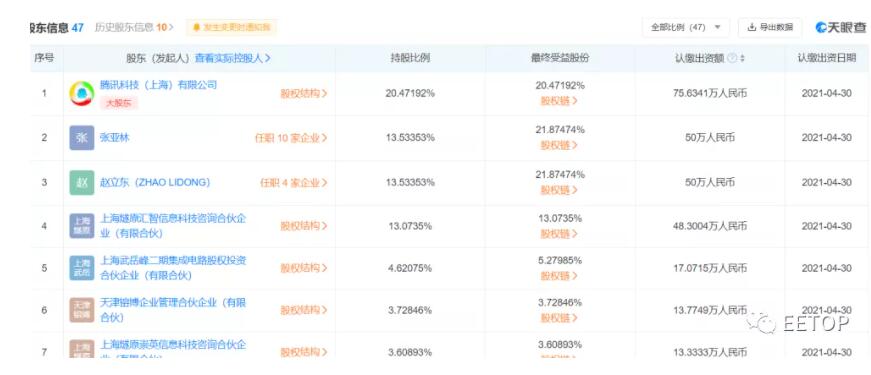
最新信息是从天眼查app获悉,8月20日燧原智能科技(深圳)有限公司成立,业务范围包括集成电路芯片设计等服务。由上海燧原科技有限公司全资持股。

我们真正想关心的问题是,对于大规模训练来说,这个芯片能做什么,而GPU却做不到。答案可能很简单,对于燧原科技最热情的支持者腾讯来说,这可能是一项中国本土技术。腾讯需要效仿其百度、阿里等国内同行,打造出(或通过收购)自己的国产人工智能硬件。
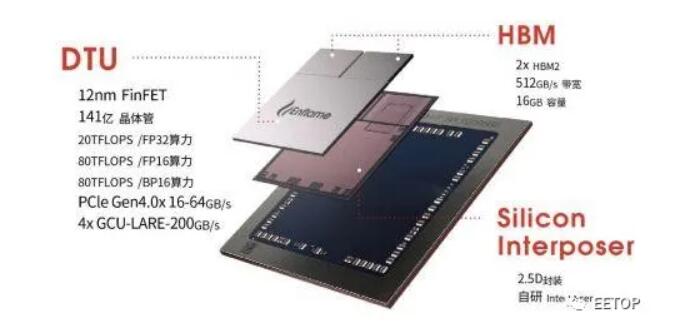
本周,我们终于在Hot Chips上看到了燧原科技基于12纳米FinFET工艺的训练SOC。下面这个图显示了 32 个"人工智能计算核心 ",它们被分成四个集群。同时,还有另外四十个主机处理模块沿着燧原科技自己的四个互连信道推送数据。每个设备有两个 HBM2 模块,带宽为 512GB/秒。
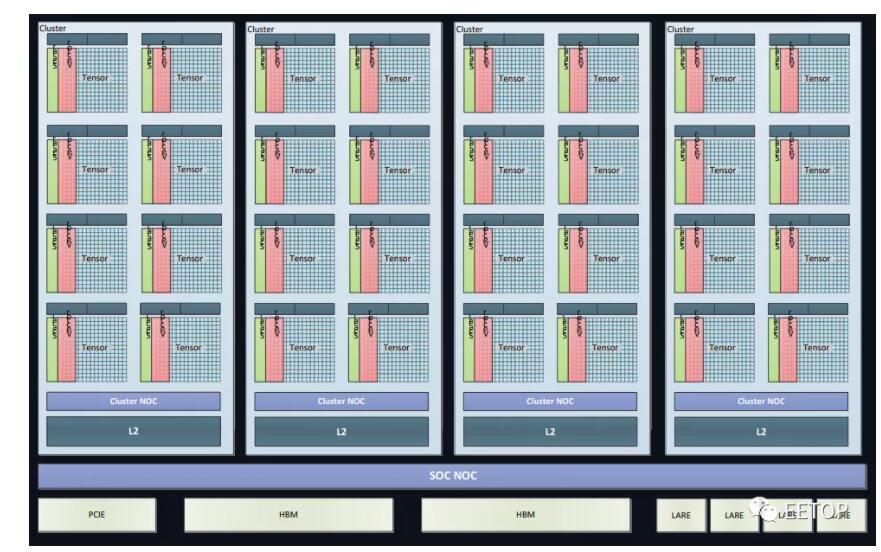
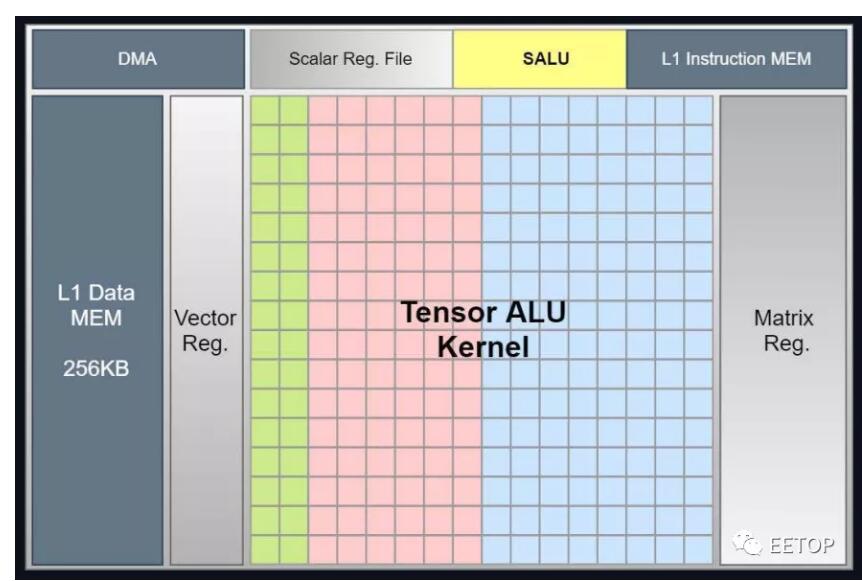
可以看出,燧原科技SoC的人工智能部分与我们以前从英伟达看到的TensorCore概念有很多共同之处,现在正被添加到其他几个CPU的设计中。燧原科技表示,它们的器件可以在 FP32 下达到 20teraflops。该器件还支持 FP16 和 Bfloat(均达到 80 teraflops 的峰值),并且可以支持具有 Int-32、18 和 8 位数据类型的混合精度工作负载。其中每一个都基于一个 256 张量的计算内核。
下面是张量单元的详细介绍:
这家初创公司提供了一款名为云隧CloudBlazer的 PCIe Gen4 加速卡,根据配置的不同,功耗在 225W 到 300W 之间,其中功耗最大的是基于开放计算项目的 OAM(开放加速模型)设计的CloudBlazer T21。除了仅限 PCIe 的设备外,燧原科技还对系统进行了封装打包,从单个节点到机架,再到具有 2D 环面互连的“pod”。
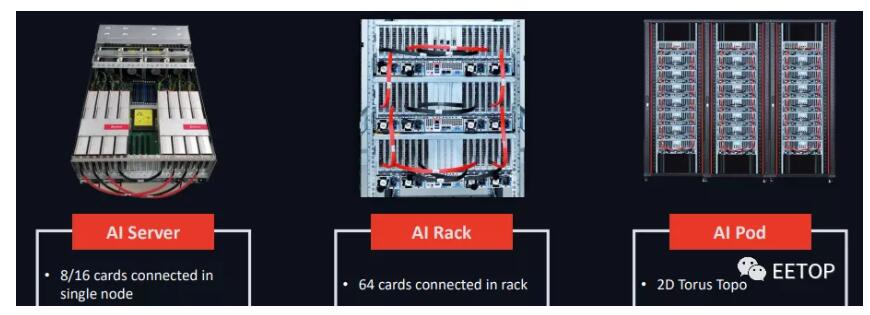
燧原科技分享了各种配置的扩展结果,显示单卡在扩展到 160 张卡时达到 81.6%,在打包到一个节点时达到 87.8%。这与我们在 GPU 可扩展性方面所看到的大致相当,尽管它不是一个条件对等的比较。
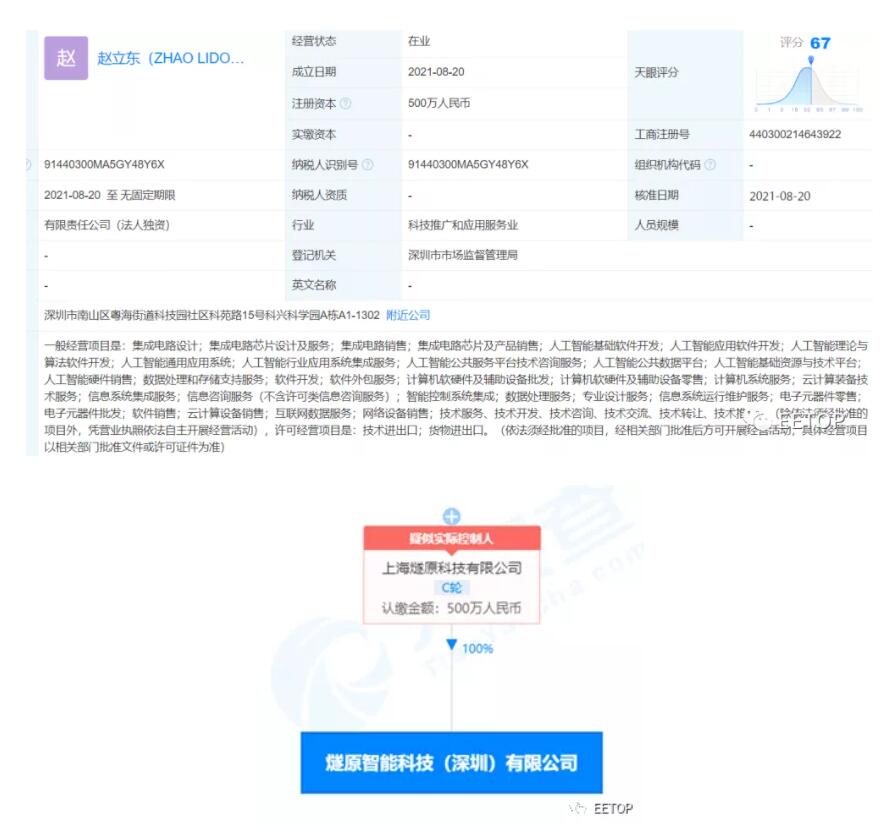
EETOP获悉,这家初创公司的创始人有着深厚的技术背景。该公司的首席执行官兼联合创始人赵立东在旧金山湾区工作了 20 年,一直从事 GPU 的研发和产品工作,不过他并不在英伟达工作。在帮助 AMD 在中国建立研发中心之前,他有七年的时间在 AMD 为其 CPU/APU 部门研发产品。在此之前,他负责开发网络安全设备,还曾在 S3 Inc. 从事 GPU 开发工作。另一位联合创始人、同时也是燧原科技的首席运营官张亚林曾是赵立东在 AMD 工作时的同事,他在AMD担任过高级芯片经理和全球器件研发技术经理,同时也从事 AMD 早期 GPU 的工作。