单元密度高于台积电5nm 20%!IBM翻倍14纳米eDRAM
2020-03-09 12:23:41 EETOP编译自wikichipz15大型机的每个抽屉内有四个z15微处理器(缩写为CP)。抽屉分为两个集群,每个CP直接与集群中的另一个CP连接。同样,每个微处理器也连接到系统控制器(SC)芯片。一个抽屉中只有一个SC芯片,并且已完全连接到机架中的所有其他五个抽屉。
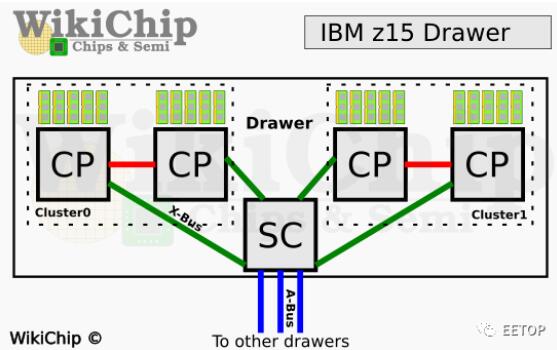
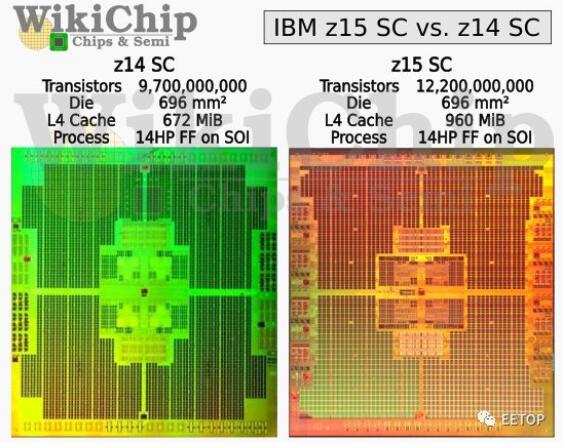
SC芯片将整个系统粘合在一起,同时提供了巨大的4级缓存。我们到底在谈论多少缓存?在单个SC芯片中尝试960 MB!与z14相比,每个SC的缓存增加了43%。微处理器本身也获得了同样令人印象深刻的增强。IBM将L3缓存从128 MiB翻倍至256 MiB。L2指令高速缓存也加倍到4 MiB。每个芯片上有12个内核,仅此一项就有24 MiB的附加L2指令高速缓存。这是最有趣的部分– IBM做到了所有这些,而没有将芯片尺寸增加一个mm²,也没有更改底层的处理技术。
SC芯片将整个系统粘合在一起,同时提供一个巨大的4级缓存。在单个SC芯片中缓存大小达到了960MB!每SC比z14多了43%的缓存。微处理器本身也得到了同样令人印象深刻的增强。IBM将L3缓存从128MB增加了一倍,达到256MB。L2指令缓存也翻倍至4MB。每个芯片上有12个核心,仅L2指令缓存就有24MB。最有趣的是IBM在没有增加芯片Die的大小,也没有更改底层的处理技术实现了缓存的大幅度的增加!
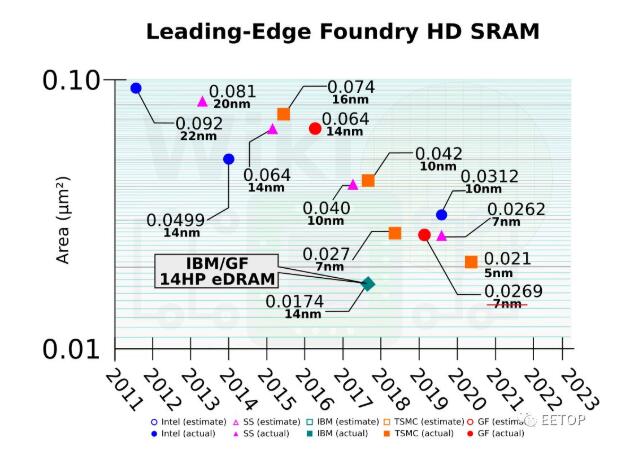
与之前的z14一样,z15最终利用了与GlobalFoundries共同设计定制的14nm SOI工艺FinFET。该工艺具有超高密度DTC eDRAM。十多年来,eDRAM一直是IBM的秘密武器。即使在其14nm工艺中,其单元尺寸也仅为0.0174μm²。目前,台积电在尚未量产的5纳米工艺中的SRAM单元为0.021μm² 。这使得IBM的14 nm eDRAM位单元的密度比迄今为止最密集的5nm SRAM单元还要高出大约20%。
那么,IBM是如何使eDRAM缓存的密度几乎翻倍的?这个要归功于IBM的物理设计团队。事实证明,到现在为止,它们的14 nm节点已经相当不错,并且位线和字线上的开销开销还不错。修补z14单元后,他们能够在这些边距内将位线和字线的长度加倍。在他们的z14上,用于L3和L4缓存的原始eDRAM宏块是1 MiB设计,由16个子阵列组成。每个子阵列包含128个字线和592个位线。在z15上,他们进行了2 MiB宏设计,该设计由八个子阵列组成,每个子阵列具有256个字线和1184个位线。
事实证明,到目前为止,他们的14nm节点已经相当不错了,而且在位线和字线上还有相当大的开销余量。通过修改z14单元格,IBM可以在这些边距内将位线和字线长度增加一倍。在z14上,L3和L4缓存的原始eDRAM宏块是由16个子阵列组成的1MB设计。每个子阵列包含128个字行和592个位行。在z15上,他们设计了一个2MB宏,由8个子阵列组成,每个子阵列有256个字行和1184位行。

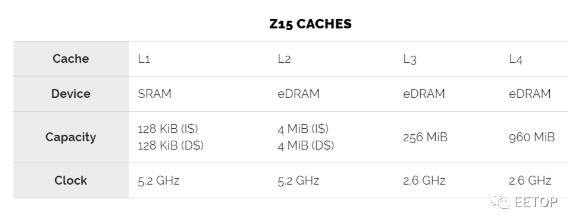
内核(L1和L2)内的缓存以内核频率运行,而内核外部和系统控制器(L3和L4)上的缓存以一半的内核频率运行。值得指出的是,此更改仅针对L3和L4缓存。每个子阵列具有由两组位线共享的感知放大器,每组具有128个单元的位线。采用电容加倍的方式实现了位线加倍,从而削弱位线信号。为了辅助线路,降低了nFET阈值电压,并引入了偏置电路以改善信号裕量。对于L3和L4缓存,延迟时间足以承受字线驱动强度和位线感测影响。但是,L2所需的访问时间不允许此方案工作。额外的L2缓存空间是通过核心内的大量物理设计工作实现的。
为了进一步节省空间,IBM更改了缓存的电源传输网络。在z14上,高电压产生电路被集成在芯片上。而在z15上,他们将这些电路置于片外。低电压电源电路则被放在宏块内。
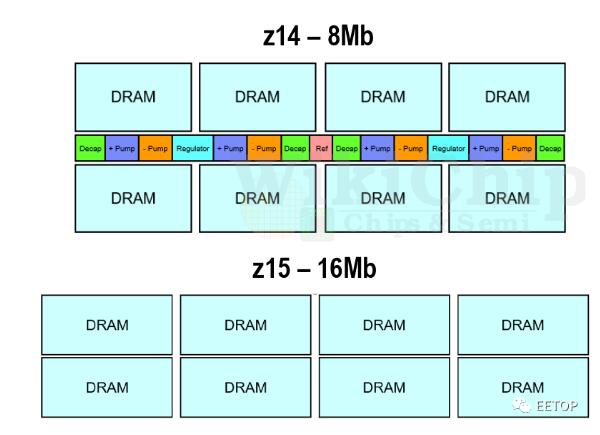
位线和字线的加倍以及子阵列的数量减半意味着可以在阵列内减少相当多的I/O开销。他们估计这些修改带来了大约30%的密度提高。与供电相关的变化使密度增加了38%。总体而言,物理设计团队设法将总有效缓存密度提高了80%(Mib /mm²)。
原文:https://fuse.wikichip.org/news/3383/ibm-doubles-its-14nm-edram-density-adds-hundreds-of-megabytes-of-cache/























