PCIe 5.0首秀!7nm IP方案已成熟!PCIe 5.0的芯片设计有多难?
2019-10-12 09:07:12 EETOP近日,芯片开发工具和硅片IP大厂新思科技(Synopsys)展示了自己的PCIe 5.0 CXL、PCIe 5.0 CCIX方案,这也是PCIe 5.0首次公开秀肌肉。

CXL、CCIX都是芯片间的互连协议,用于连接处理器和各种加速器(标量/矢量/矩阵/空间等架构),并保持低延迟的内存和缓存一致性,都面向异构计算架构。
CXL 1.0/1.1、CCIX 1.1版本都引入了PCIe 5.0,利用其单链路32GT/s高带宽的优势,并原生支持不同的链路带宽。

新思科技最近推出的DesignWare CXL IP方案可采用16nm、10nm、7nm工艺制造,支持16个PCIe链路,包括CXL 1.1控制器、硅验证的PCIe 5.0控制器、硅验证的32GT/s PHY物理层、RAS、VC验证IP。
DesignWare CCIOX 1.1 IP方案尚未正式发布,不过从展示来看,其功能已经完备,PCIe 5.0已经很好地融入其中。
两套展示方案都基于FPGA和特殊设备,而没有使用真实的芯片,所以还只是功能上的演示,距离实际产品尚还需要一些时日,但这无疑表明,PCIe 5.0会比我们想象的来得更快。
旧的 PCI Express (PCIe) 技术正在加速向最新的 5.0 版本过渡,片上系统 (SoC) 设计人员会发现推出速度比使用 PCIe 4.0 时更快。在近期的 Synopsys 网络研讨会上,观众的问卷调查答案显示,虽然许多 PCIe 4.0 设计的启动工作井然有序,但一些设计人员正在跨过 PCIe 4.0 并直接转向 PCIe 5.0 设计。调查还显示,许多尚未改用 PCIe 5.0 设计的人员也会在未来 12 个月内改用。
每一代 PCIe 的带宽都会增加一倍,现在已经从 16 GT/s PCIe 4.0 变成 32 GT/s PCIe 5.0。最近发布的 0.9 版 PCIe 5.0 基本规范锁定了针对规范的功能变更,使设计人员可以放心地着手设计。
除了带宽加倍之外,该规范还提出了一些新功能,例如加快链路启动的均衡旁路模式、有助于避免突发错误(可能是由更高的判决反馈均衡 (DFE) 分接比引起的)的预编码支持,以及支持进行串扰模拟的环回增强。随着 PCIe 5.0 技术的迅速普及,SoC 设计人员应该了解并考虑他们将面临的一些关键设计挑战,例如增多的信道损耗、复杂的控制器考量、PHY 和控制器集成、封装和信号完整性问题以及建模和测试要求。本文概述了改用 PCIe 5.0 接口所面临的设计挑战,以及如何使用成熟的 IP 来成功克服挑战。这种 IP 经过设计和测试,可满足 32 GT/s PCIe 5.0 主要功能的要求。
将数据速率从 16 GT/s 加倍到 32 GT/s 后,奈奎斯特频率也会加倍到 16 GHz,从而加重频率相关的插入损耗。此外,频率升高时增加的电容耦合会加重信号的干扰或噪声,使串扰比 PCIe 4.0 信道中的串扰更严重。这些因素累积在一起,使 PCIe 5.0 信道成为 SoC 设计人员遇到的最具挑战性的非归零 (NRZ) 信道。
选择的 PCB 材料(FR4、Megtron、Tachyon、iSpeed)会对各个区域的插入损耗产生巨大影响。图 1 是一个简单示例,显示了 16 GT/s(8 GHz 奈奎斯特)和 32 GT/s(16 GHz 奈奎斯特)数据速率下,穿过各种 PCB 材料的 16 英寸走线的插入损耗。FR4 是一种常见且使用广泛的材料,其插入损耗从 8GHz 奈奎斯特(第 4 代数据速率)时的 19.34 dB 增长为 16 GHz 奈奎斯特(第 5 代数据速率)时的 33.44 dB。因此,用于 PCIe 5.0 系统的 FR4 变得完全不实用,因为 16 英寸不是很长,并且电路板损耗只是总信道损耗的一小部分(PCIe 5.0 规范定义的不超过约 36 dB),并且还包括封装、多个 PCB、连接器等。现实中的 PCIe 5.0 系统需要比 FR4 更好的材料。
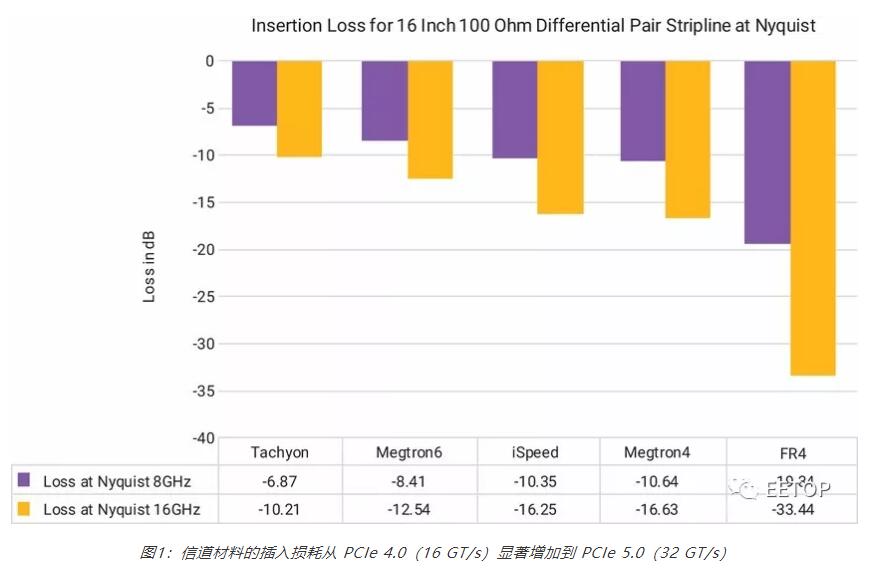
图1:信道材料的插入损耗从 PCIe 4.0(16 GT/s)显著增加到 PCIe 5.0(32 GT/s)
除了信道材料之外,信道配置也会严重影响总插入损耗和信道的整体凹凸情况,因为每次从一种材料过渡到另一种材料时都会引起信号反射。例如,最简单的一种信道是穿过基板或电路板的芯片到芯片接口,它不带任何额外的连接器,可呈现平滑的插入损耗曲线。但是,在一路添加更多连接器之后,信道性能就会迅速变差。例如,现实中的芯片到芯片信道可能包含一个夹层连接器,或者是使用转接卡和附加卡的两个连接器,也可能是两个以上的背板连接器和一个夹层连接器。每次将连接器添加到信道时,发送器和接收器都必须克服额外的信道损耗,并且必须能够均衡造成主光标显示许多单位间隔的干扰源。这通常需要复杂的多抽头 DFE 接收器设计,加入固定和浮动抽头,旨在完全均衡信道并在 32 GT/s 的速度下开启眼图。
设计人员将尽最大努力预判这些挑战,并设计一个具有足够裕量的稳健系统,保证实现无错数据传输。设计 PCIe 5.0 时,设计人员必须能够利用 PCIe 4.0 规范中引入的 RX 通路裕量来评估实际系统中的实际接收器容限。虽然 PCIe 4.0 规范仅需要在时序(水平眼图开度)上使用 RX 通路裕量,但 PCIe 5.0 规范 (32 GT/s) 也需要将 RX 通路裕量用于电压(眼高)以帮助确保系统的稳定性。
配置 PCIe 5.0 控制器时,数据有效负载大小 对于优化性能和吞吐量具有重要意义。由于每个分组的开销都相对固定,通常每个事务层分组 (TLP) 大约占用 20 到 24 个字节,小的有效载荷表现低效,因此控制器必须尽量留出足够大的有效载荷来满足必要的吞吐量。PCIe 规范定义的有效载荷高达 4096 字节,而行业平均值通常仅为 256 字节。但是,设计人员需要为其目标应用选择合适的最大有效载荷,以实现 PCIe 5.0 控制器的理想性能水平,同时还要了解 PCIe 链路合作伙伴支持的有效载荷的潜在范围。设计人员还必须明白,确定可实现的吞吐量时必须考虑 TLP 标头开销:LCRC、序列和成帧、潜在的 ECRC,以及 128b/130b 编码造成的损耗。
为了在 PCIe 5.0 系统中实现最佳性能,设计人员必须确定等待的未发布请求 (NPR) 的最大数量,并确保提供足够数量的标签。标签数量是控制器的一个属性,因此必须根据系统要求正确设定数量。最新版本的 PCIe 5.0 规范支持使用 10 位标签,该标签最多可支持 768 个唯一标签(由于保留了一些位值,因此预期限值为 1024)。选择的标签太少就会对性能产生负面影响。随着总往返传输时间或延迟的增加,在 32 GT/s 的速度下保持系统最佳性能所需的标签数量也会增多。所需的标签数量还会受到保持最大吞吐量所需的有效载荷和最小读取请求大小的影响。PCIe 5.0 所需的标签数量也更大,因为在 32 GT/s 时系统吞吐量更高。
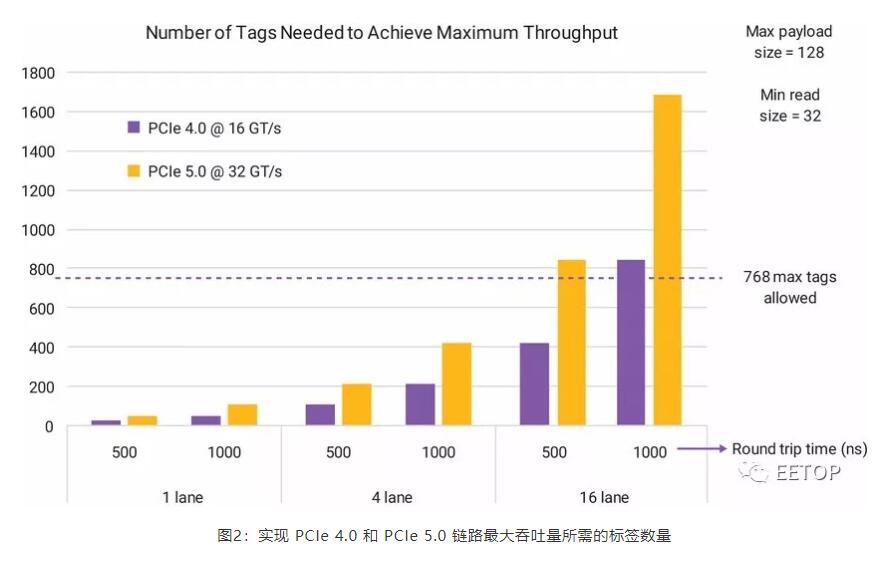
图2:实现 PCIe 4.0 和 PCIe 5.0 链路最大吞吐量所需的标签数量
理想的情况是由同一家供应商实现完整的 PHY 和控制器 IP 解决方案。在混合和匹配不同供应商的解决方案时,设计人员必须考虑某些集成难题。英特尔已经为 PCIe (PIPE) 定义了一个称为 PHY 接口的规范来帮助实现这种集成,但由于 PIPE 规范发生了更改,所以务必要了解该接口及其实现的详情。PIPE 4.4.1 接口不明确支持 PCIe 5.0 技术,因为它要处理更高的速度,就需要追加寄存器位。如果设计人员期望使用这个版本的 PIPE 规范,设计人员和 IP 供应商就必须处理许多技术细节,这可能很麻烦。新的 PIPE 5.1.1 规范为 PCIe 5.0 技术提供了第一个真正的支持。它具有许多新功能,设计人员必须全面了解:
低引脚数接口将以前的带外引脚改为寄存器位,从而简化了 PHY 控制器接口。最初引入这个概念是为了采用一组数量有限的引脚来传输 PCIe 4.0 RX 通路裕量信号,而后它在 PIPE 5.1.1 中得到极大的扩展,提供了大幅简化的接口。
SerDes 架构有效地将大部分物理编码子层 (PCS) 功能从 PHY 转移到控制器中,并已作为 PIPE 5.1.1 的“必需”模式添加进来。SerDes 架构促使不需要 PCS 功能的多标准 PHY 获得采用。推荐但不强求为 PCIe 5.0 保留原始 PIPE 架构,因此对 SerDes 架构的支持成为需要考虑的重要因素。
添加了 64 位 PIPE 选项,但只用于 SerDes 架构。这样能够支持 PIPE 接口进行低速操作,但由于缺少 1024 位控制器,要用它实现 16 信道就变得不切实际了。即使采用原始 PIPE 架构运行时,Synopsys 也能支持 64 位 PIPE。
始终都要权衡数据路径宽度和 PIPE 接口处时序收敛的频率。设计人员拥有的 PCIe 4.0 的一些选项在 PCIe 5.0 上可能不再可用。在 32 GT/s 时,PIPE 接口必须至少为 32 位宽,以避免超过 1GHz 的时序收敛。64 位 PIPE 接口可以作为一个选项,支持在 500 MHz 时的时序收敛,但它不适合最宽的接口。要想理解这一点,请考虑表 1 中所示的一些配置。对于 32 GT/s 时的 PCIe 5.0,可以排除 16 位 PIPE,因为它需要 2GHz 的时序收敛,这一频率极难甚至不可能达到。这样还剩下 32 位或 64 位 PIPE 选项。但是,如果设计人员通过实现 x16 链路来利用最大可用吞吐量,那么就只剩下一个选项了:具有 32 位 PIPE 接口和 1GHz 时序收敛的 512 位控制器。否则,就需要 1024 位控制器架构,目前任何 IP 供应商都无法供应该架构。

表格 1:收敛时序时,关键是要在速度和宽度之间达成可以实现的权衡
因此,对于按照 32 GT/s 运行的 x16 链路,必须使用 512 位控制器,这使得设计人员必须使用经过硅验证和测试的 512 位控制器 IP 架构。改用 512 位架构还意味着每个时钟周期都可以有多个数据包。这意味着控制器架构必须能够正确处理 TLP 的序列化和排序,避免给设计人员的应用逻辑带来不必要的复杂性。这就需要采用经过验证的 512 位解决方案,最好是利用标准库(而不是昂贵的高速库)在 1GHz 的频率时,在 PIPE 接口成功展示时序收敛的解决方案。
为保证封装和信号完整性,必须设定并满足新的插入损耗和串扰规范,以适应更快的 32 GT/s 数据速率和 16 GHz 奈奎斯特频率。必须在封装外形中细致处理走线长度和布线,以避免串扰冲突并满足新的插入损耗和串扰规范。配电也是一个重要因素,因为 32 GT/s 设计需要在封装时降低电感。由于浪涌电流 (di/dt) 增大,必须降低电感才能将电压噪声保持在同等水平。
32 GT/s 数据速率下的反射和串扰问题更加突出,而且必须仔细分析垂直互连访问等信号路径中的所有不连续性。垂直互连访问包括 VIA、球栅阵列 (BGA) 球、连接器、隔直电容等。VIA 区域中的发送器和接收器布线如果不恰当,就会增加相邻信号或通路之间的串扰。设计人员必须尽量保持走线的最大间距,确保即便在如此拥挤的 VIA 区域也能避免串扰。
随着数据速率的提高,所需电源电流的幅度和频率也会增加,但维持稳定供电电压的难度仍然基本相同。例如,一条通路中的电源状态变化会为另一条在连续发射模式下运行的通路产生浪涌电流,从而产生很大的供电电压峰值。设计人员必须能够对电力传输网络进行适当的分析,以便:
利用足够的去耦电容和封装/电路板电感,验证所有通路的噪声是否符合交流纹波规范
检查板载滤波器组件是否具有效果最好的频率响应,并能根据需要进行改进
确认一条通路中的模式变更不会影响另一条通路中的操作
了解封装和信号完整性问题,并在必要时与在设计封装和电路板方面经验丰富的公司合作实现高数据速率
建模与测试
准确仿真 PCIe 5.0 系统的唯一方法是针对 PHY TX 和 RX 接口使用输入/输出缓冲器信息规范算法建模接口 (IBIS-AMI) 模型。设计人员可以将其 PHY IP 供应商的 IBIS-AMI 模型与封装、PCB 和连接器模型合并为一个完整的信道模型,用来运行精确的系统仿真。图 3 展示了 IBIS-AMI 模型仿真(左侧)与通过系统板仿真实际测量的眼图(右侧)之间的对比。IBIS-AMI 仿真准确性高,与实际硅数据相符。

图3:要在系统仿真期间获得准确结果,必须构建 IBIS-AMI 模型
对于量产设备,在 32 GT/s 速率下的制造测试需要能够验证链路的快速测试。此类测试通常使用内置环回模式、图形发生器和接收器(集成在 PHY 和控制器 IP 中)。一些测试设置也可以利用通常并入 PCIe 5.0 PHY IP 的内置示波器功能。应当利用 PCIe 控制器 IP 解决方案的内置调试、错误注入和统计功能来完成稳定的系统测试。这有助于确保固件和软件正确预测可能遇到的任何潜在的实际系统问题。
对于 PHY 测试,如果设计人员需要详细了解 32 GT/s PHY 的性能,通常会使用高速示波器来测量 TX 抖动和其他参数。改用 32 GT/s 意味着示波器带宽也需要提高,但要提高多少呢?即便信号上升时间会催生这一要求,但实际的 PHY 通常也会有一些上升时间限制,以便保证电源具有实用性。因此,50 GHz 示波器通常就具有足够的带宽,可以正确分析 32 GT/s 信号。
随着 32 GT/s PCIe 5.0 技术的加速采用,SoC 设计人员必须在转换时了解并应对一些设计挑战。32 GT/s 设计具有极具挑战性的 NRZ 信道,这些信道具有极高的损耗和波动性,引发大量的不连续性,致使插入损耗高达 36dB 以上。PCIe PHY 设计必须包含独特的架构,配备经过验证的模拟前端、连续时间线性均衡器和先进的多抽头决策反馈均衡器,可以无缝协作以缓解设计问题。PHY 和控制器的集成需要更仔细的规划,才能确保 PIPE 接口的兼容性,并且方便完成 1GHz 时的时序收敛。
为了实现最高性能,必须仔细选择和管理几个 PCIe 5.0 控制器配置选项。应探索进行架构权衡,平衡最大有效载荷大小、读取请求大小、标签数量和其他重要的控制器配置设置。
必须对芯片和封装进行仔细的信号和电源完整性分析,并且必须仿真整个信道,确保在 32 GT/s 时达到性能目标。
通过与 Synopsys 合作,可以缓解甚至消除这些新难题,Synopsys 是一个久经考验且值得信赖的 IP 合作伙伴,拥有多年成功开发优质 PCIe IP 的业绩记录。适用于 PCIe 5.0 的 Synopsys DesignWare® IP 全套解决方案包含控制器、PHY 和验证 IP。经过硅验证的 IP 支持 PIPE 4.4.1 和 5.1.1 规范,使用的架构可承受超过 36dB 的信道损耗,并能直接实现 1GHz 的时序收敛。这种控制器具有高度可配置性,支持多种数据路径宽度,包含经过硅验证和测试的 512 位架构,并具有业界最广泛的 RAS-DES 功能,可实现无缝启动和调试。这种经过硅验证的解决方案已被众多客户采用,可提供准确仿真 PCIe 系统所需的完整 IBIS-AMI 模型。