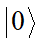人工智能革命:深度学习改变世界
2017-01-04 19:57:56 财富中文网近几日,疑是 AlphaGo的Master在网络上血洗”世界围棋界,面对人类顶尖高手豪取54连胜。人工智能看来又上升了一个高度。
过去四年间,人们肯定已经注意到,我们身边的很多日常科技正在发生着日新月异的巨大进步。
最明显的是,智能手机语音识别功能的识别质量与过去比有了巨大突破。我们只需对着手机说出妻子或者丈夫的名字,就能毫不费力地接通他们的电话,而不至于被错接到铁路公司或者怒气冲冲的前女友或男友的电话上。事实上,我们目前正在越来越多地通过语音识别功能(例如亚马逊的Alexa、苹果的Siri、微软的Cortana、以及谷歌推出的大量语音交流功能)与计算机进行沟通。中国搜索巨头百度称,在过去18个月内,使用语音识别交互功能的用户数量增加了两倍。
机器翻译及其他语言处理工具的质量与以前相比也有了巨大提升。每个月,谷歌、微软、Facebook和百度都会推出新的语言处理功能。谷歌翻译(Google Translate)目前能够提供32种语言间的语音翻译,以及103种语言间的文本翻译(包括宿务语、伊博语和祖鲁语等小语种)。谷歌Inbox能够为收件箱里的电子邮件预设3条自动回复。
图像识别技术也在突飞猛进。以上四家企业都已推出了无需输入关键词就能帮你搜索或自动整理照片库的功能。例如,你可以迅速筛选出画面里有狗的照片、下雪天拍摄的照片、或者具有抽象特性——例如有人拥抱——的照片。四家公司都在开发能够在数秒内为照片自动撰写图片说明的功能。
这些功能貌似简单,实际上背后却是极为复杂的技术。想想看,为了筛选出有狗的照片,软件就必须识别从吉娃娃到德国牧羊犬等所有品种的狗,还必须考虑狗的画面上下颠倒、狗的一部分模糊不清、狗位于画面左侧或右侧、起雾或下雪、晴天或阴天等等种类繁多的情况。与此同时,还必须排除掉狼和猫。而这一切仅仅只用到图片像素。那么,这一切都是怎么做到的?

神经网络如何识别出图片中有狗?
1. 训练
训练阶段中,让神经网络处理数以千计的有标签动物图片,并学习如何将其分类。
2.输入
将一张无标签图片输入相关网络。
a.第一层 神经元对边线等图像元素做出反应。
b.更高层 神经元对更多复杂结构做出反应。
c.最顶层 神经元对非常复杂抽象的概念做出反应,即分辨出不同动物。
3.输出
神经网络猜出最有可能是什么物体。
图像识别的应用范围已经远远超出流行社交App的范畴。有医疗初创公司称,他们很快就能使用计算机以超过放射科医师的速度和准确度判读X光、核磁共振和CT图像、以创伤更小的方式诊断早期癌症、或者研发治疗重大疾病的药物。高质量的图像识别技术是机器人、自主化无人机、以及自动驾驶汽车技术(这一技术意义重大,于6月成为本刊封面故事的主题)取得进一步发展的关键。目前,福特、特斯拉、优步、百度和谷歌母公司Alphabet都在加紧测试其自动驾驶样车在公路上的表现。
大多数人都不知道,上面的这些突破实际上都能归拢到单独一项突破上。它们背后的英雄都是人工智能(artificial intelligence,简称AI)家族树上的一个分支——深度学习。有些科学家仍然喜欢以它原来的名称——深度神经网络——来称呼它。
神经网络最神奇的地方在于,它的能力属于自动生成,从来没人能编写出一套计算机程序来实现上述描述过的任何一项任务,实际上也没人能做到这一点。为了构建神经网络,需要计算机内安装一套学习性算法,并让其处理输入的海量数据(例如,数十万张图像,或者持续数年时间的巨量语音样本)对它进行训练,从而让计算机自己学会如何找出所需物体、词汇或句段。
简言之,这种计算机能够自我学习。“最终是要让软件自己写软件,”图像处理行业巨头英伟达公司CEO黄仁勋说。英伟达公司在大约5年前对深度学习投下了巨额赌注。

英伟达公司CEO黄仁勋
神经网络并非一个新兴概念。神经网络起源于1950年代,在1980和1990年代,神经网络算法取得了多项重大突破。与当时不同的是,今天的计算机科学家手中握有两件超级武器:极为强大的计算能力和极为庞大的数据库——今天的互联网上每天流转着天文数字的图像、视频、音频和文本——从而为神经网络大显神威铺平了道路。“这堪称深度学习领域的寒武纪生物大爆发,”硅谷风投公司安德森-霍洛维茨公司(Andreessen Horowitz)合伙人弗兰克·陈(Frank Chen)说,他提到的寒武纪生物大爆发是高等动物物种突然暴增的时期。
这一系列技术突破带来了一波接一波的创业浪潮。市场研究机构CB Insights发布报告称,上个季度,人工智能初创企业获得的股权投资超过10亿美元,创下历史季度新高。CB Insights还称,2016年第二季度,人工智能初创企业获得121宗投资,而2011年同时期这一数字仅有21宗。从2011年到2016年,人工智能初创企业共获得75亿美元投资,其中60多亿美元都是在2014年以后到位的。(9月末,人工智能行业五大巨头——亚马逊、Facebook、谷歌、IBM和微软共同组建了非营利机构人工智能伙伴计划(Partnership on AI,该机构的使命在于促进公众对于人工智能的了解,并对与人工智能有关的道德问题和最佳实践开展研究。)
谷歌发言人表示,2012年,谷歌的深度学习项目仅有两个,而今天则已超过1,000个,覆盖了包括搜索、安卓、Gmail、翻译、地图、YouTube和自动驾驶等所有产品领域。2011年,当时采用人工智能技术,没有涉及深度学习的IBM沃森系统在Jeopardy!问答比赛中两度夺桂。而据沃森部门的CTO罗伯·海(Rob High)表示,目前沃森所有30个服务组件都已由深度学习技术进行了强化。
五年前对深度学习一无所知的风险资本今天已经不愿意投资未采用深度学习技术的初创企业。弗兰克·陈说,“在我们当今所处的时代,对于设计复杂软件应用的程序设计师,”人们会问,“你的应用有没有自然语言处理版本?我能和你的应用直接对话吗?因为我不想浪费时间点击菜单。”
已经有公司开始把深度学习融入其日常工作流程。微软研究院联席院长彼得·李表示:“我们的销售团队正在使用神经网络自动筛选主推的产品和重点开发的客户资源。”
硬件世界也已经感受到了这股力量。计算能力出现爆炸式激增的原因不仅在于摩尔定律,还在于2000年代末英伟达图像处理器(GPU)- 最初为3D游戏开发的高性能芯片 - 的计算能力超过传统中央处理器(CPU)20-50倍,从而为深度学习计算的开展铺平了道路。今年8月,英伟达宣布,其数据中心业务的季度收入达到1.51亿美元,比去年同期增长一倍以上。英伟达首席财务官对投资者表示:“目前,绝大部分增长来自深度学习。”在为时83分钟的电话会议中,“深度学习”一词出现了81次。
芯片业巨头英特尔也在跃跃欲试。过去两个月,英特尔收购了Nervana Systems (收购价格超过4亿美元)和Movidius(收购价格未透露)两家提供定制化深度学习计算技术的初创公司。
谷歌在5月表示,在过去的一年里,他们一直在秘密使用名为一款名为Tensor处理器(TPU)的定制芯片运行采用了深度学习技术的软件应用。(Tensor是指类似矩阵,在深度学习计算中经常相乘的数字序列。)
事实上,各大企业似乎到达了另一个拐点。百度首席科学家吴恩达表示:“有很多标普500公司CEO都后悔没能早点时间启动互联网战略。我敢说在5年后,会有很多标普500公司CEO后悔没能早点时间启动人工智能战略。”

百度首席科学家吴恩达
吴恩达认为,以深度学习为基础的人工智能的重要性甚至超过了互联网。“人工智能是新时代的电力,”他说。“100年前,电力改造了所有行业的面貌,人工智能也必将如此。”
深度学习实质上是一个非常细分的概念。 “人工智能”是由大量技术 ——包括基于逻辑和规则的传统技术——所构成的一个技术组合体,在人工智能的辅助下,计算机和机器人能够以模拟人类思维的方式解决问题。作为人工智能的一个分支概念,机器学习是一个由高度复杂但重要的数学技术构建的完整工具包,在此工具包的协助下,计算机能够通过学习经验而提高执行任务的质量。而深度学习则是机器学习下属的一个更为细分的概念。
深度学习的作用可以简单用 “输入A,输出B”来概括,吴恩达说。“你输入音频文件,输出字幕。这就是语音识别。”假如用数据对软件不断进行训练,就会得出无穷无尽的可能结果,他说。“你输入电子邮件,会输出:这是一封垃圾邮件吗?”输入贷款应用,会输出客户偿还贷款的可能性。输入对一个汽车车队的使用规律,则会输出把下一辆车派到哪里的建议。
从这个角度看,深度学习拥有改造所有行业的能力。“计算机视觉技术继续发展下去就会引发极其重大的变革,”谷歌大脑项目主管杰夫·迪恩(Jeff Dean)说。他有些神情不安地加了一句:“现在计算机已经有了眼睛。”
这是不是意味着“奇点”的到来已经迫在眉睫了吗? “奇点”是指科学家设想的,超级智能机器无需人类介入就能够自我改造,从而把低能的人类踩在脚下,造成可怕后果的那个时刻。
其实大可不必杞人忧天。尽管神经网络擅长于图像识别——在这件事上可能比人做得更好,但它却没有独立思考的能力。
点燃这场革命的最早火花出现在2009年。那时,神经网络技术开创者、多伦多大学的杰弗里·辛顿(Geoffrey Hinton)受邀走访了微软首席研究员邓力的实验室。当时,在辛顿研究成果的启发下,邓力的研究团队正在实验利用神经网络进行语音识别。“实验结果让我们大吃一惊,” 微软研究院联席院长彼得·李说到。“第一个版本就把准确率提高了30%。”
彼得·李说,2011年,微软将深度学习技术引入其商业化语音识别产品。谷歌于2012年8月启动类似研究项目紧追其后。
真正的转折点发生在2012年10月。在一场于意大利佛罗伦萨召开的研讨会上,斯坦福大学人工智能实验室主任、知名年度ImageNet计算机视觉大赛的创办者李飞飞宣布,辛顿的两位学生已经发明了能够以比最强竞争对手高一倍准确率识别物体的软件。“这是一项伟大的成就,”辛顿回忆说,“让很多曾经对人工智能批评有加的人转变了看法。”(上年度大赛中,一个人工智能参赛者的表现超过了人类。)
尽管解决图像识别问题只是人工智能时代的一个开始,但却引发了一股人才争夺战的热潮。谷歌把辛顿和他参与大赛的两个学生招至麾下;Facebook招募了曾在1980和1990年代写出大赛获胜算法的法籍深度学习元老燕乐存(Yann LeCun);百度则聘请了原斯坦福人工智能实验室主任吴恩达,他曾在2010年领导专注于深度学习技术的谷歌大脑项目。
今天,人工智能人才争夺战仍在愈演愈烈。微软的彼得·李说,“这一领域的人才争夺到了疯狂的地步。”他说,顶级人工智能专家的薪酬“和国家橄榄球联盟球星不相上下。”
现年68岁的杰弗里·辛顿最早是在爱丁堡大学研究生院攻读人工智能相关学位时知道神经网络这个概念的。由此,本科在剑桥大学学习实验心理学的辛顿对神经网络产生了极大兴趣。神经网络是一种模仿大脑神经元工作原理的软件结构。当时,几乎没人对神经网络感兴趣。“所有人都认为这是不可能实现的,”他回忆说。但是辛顿却没有气馁,而是迎难而上。
神经网络可以让计算机和儿童一样通过经验自我学习,而不是让人工编写的程序告诉它怎么做。“当时,大多数人工智能都是由逻辑驱动的,”他回忆说。“但是,逻辑是人类在很大年龄才具备的东西。两三岁的儿童不按逻辑行事。神经网络就是智力能够超越逻辑的一个范例。”(有趣的是,逻辑曾是辛顿一家长期以来一直遵循的法则。他的家族涌现过大量杰出科学家,他是19世纪数学家乔治·布尔[George Boole]的曾孙,布尔搜索、布尔逻辑和布尔代数即以他的名字命名。)
1950和1960年代,神经网络曾经是计算机科学中的一个时髦词汇。1958年,康奈尔大学研究心理学家弗兰克·罗森布拉特(Frank Rosenblatt)参与美国海军资助的一项研究计划,在布法罗的一家实验室建成了一个神经网络原型,他称之为“Perceptron”。这个原型使用一台体积占满整个房间的穿孔卡片计算机。50次实验后,它学会了识别左侧穿孔和右侧穿孔的卡片。《纽约时报》当时刊登了一篇报道:“海军近日发现,一台原型电子计算机有可能学会走路、说话、观察、写作、自我复制、并意识到自身的存在。”
Perceptron的软件只有一层类似于神经元的节点,它的能力十分有限。但是,研究人员认为,如果具备多层或深层的神经网络,它就能做更多事情。
辛顿向我们解释了神经网络的基本原理:假设一个神经网络正在解析照片图像,某些照片上有鸟。“像素数据输入后,第一层神经元将会探测各个微小的边缘: 一侧较暗,另一个较亮。”第二层神经元将分析来自第一层的数据,并学会探测“两个侧边以一定角度交接的边角,”他说。例如,其中一个神经元将会识别出鸟喙的角度数据。
下一层神经元“将会发现更为复杂的特征,例如一个圆内的大量边线。”一个神经元可能会识别出鸟头。位于更下一层的神经元将会在类似鸟头的圆附近发现反复出现的类似鸟喙的锐角。“这正是鸟头的明显标志,”辛顿说。以下每一层的神经元都会识别出更为复杂和抽象的结构,直至最后一层得出被识别物体是一只“鸟”的结论。
然而,为了达到学习目的,神经网络需要做的不只是把信息发送到每层神经元而已。它必须判断最后一层是否得出了正确结果。如果结果错误,就会逐层反向发送信号,让每层的神经元重新调整其触发规律,从而改善识别质量。这就是为何称为“学习”的原因。
深度学习历史上的重要时刻
1958年
康奈尔大学心理学家弗兰克·罗森布拉特推出基于占满整个房间的计算机的单层神经网络Perceptron。
1969年
人们对神经网络失去兴趣,麻省理工学院人工智能权威马文·明斯基与他人共同撰写一本著作,对神经网络的现实性提出质疑。
1986年
神经网络开创者杰弗里·辛顿及他人发现一种训练多层神经网络纠正错误的方法,催生了很多类似的研究成果。
1989年
当时就职于贝尔实验室的法国科学家燕乐存对神经网络开始进行一系列基础性研究,研究成果成为图像识别技术的基石。
1991年
德国科学家赛普·霍希雷特和约根·施密德霍伯研制出具有记忆功能的神经网络,这一技术在日后的自然语言处理中展现了优势。
1997
IBM深蓝采用传统人工智能技术击败了国际象棋世界冠军卡斯帕罗夫。
1990年代中期
其他机器学习技术快速发展,神经网络再次陷入停滞。
2007年
李飞飞创建ImageNet,整理了1400万张带标签图片供机器学习研究用途。
2011年
微软的语音识别产品采用了神经网络。
IBM沃森采用传统人工智能技术在Jeopardy节目中打败两位冠军。
2012年6月
谷歌大脑公布“猫实验”:由1000万张YouTube视频截图训练的神经网络学会了如何从图片中找到猫。
2012年8月
微软的语音识别产品采用了神经网络。
2012年10月
辛顿的两位学生设计的神经网络以几大优势夺取了年度ImageNet冠军。
2013年5月
谷歌使用神经网络技术改进图片搜索质量。
2014年
谷歌以6亿美元收购DeepMind,一家将深度学习和强化学习结合起来的初创企业。
2015年12月
微软团队利用神经网路在ImageNet挑战赛中战胜了人类选手。
2016年3月
DeepMind的AlphaGo利用深度学习,以4比1的比分击败了围棋世界冠军李世石九段。
2017年1月
疑是 AlphaGo的Master在网络上血洗”世界围棋界,面对人类顶尖高手豪取54连胜。
1980年代初,辛顿正在忙着解决多层神经元问题。当时做同样工作的还有刚刚在巴黎上研究生院的法国科学家燕乐存。燕乐存无意中读到了辛顿于1983年撰写的一篇讨论多层神经网络的论文。“当时使用的不是这些术语,” 燕乐存回忆说,“当时你要是用‘神经元’或者‘神经网络’这些词,论文就很难发表。所以他当时用了一些含混不清的术语以求通过编辑的筛选。但我当时就感觉这篇论文非常非常有趣。” 两人在两年后会面并一见如故。
1986年,辛顿和两名同事合作撰写了一篇影响深远的论文,为解决纠错问题提供了算法。“他的这篇论文实际上是第二波神经网络浪潮的奠基石,” 燕乐存说。果然,这篇论文引燃了业内人士的巨大兴趣。

攻读完辛顿的博士后学位后,燕乐存于1988年加入美国电报电话公司的贝尔实验室,在以后的10年里,他做了许多基础性工作,其中某些成功至今仍在图像处理任务中得到应用。1990年代,当时为贝尔实验室分支机构的NCR公司推出了一种可以帮助银行识别支票上手写数字的实用化神经网络设备,并大获成功,燕乐存表示。与此同时,两位德国科学家——赛普·霍希雷特(Sepp Hochreiter,目前就职于林茨大学)和约根·施密德霍伯(Jürgen Schmidhuber,瑞士卢加诺人工智能实验室副主任)独立推出另一种算法。在20年之后的今天,这种算法成为自然语言处理应用的基础。
尽管取得了上述进展,但在1990年代中期,神经网络再一次陷入低谷,取而代之的是更加适合当时计算能力的其他机器学习技术。这种情况一直持续了将近10年,直到后来计算能力增大了三四个数量级,且有科学家发现了GPU加速现象才出现改观。
但是另一个要素仍然不足:数据。尽管互联网此时已经大行其道,但大多数数据 ——尤其是图像数据 ——都没有备注标签,而数据标签是训练神经网络的必需。此时,斯坦福人工智能教授李飞飞出现了。“我们的目标是,大数据将改变机器学习的方式,”她在一次采访中表示。“数据将推动学习。”