
手机扫码关注,后台输入EETOP BBS 用户名,奖励200信元
AMD大跃进:未来4年,能效提高30倍!
2021-09-30 12:21:31 EETOP编译自tomshardware
AMD 今天宣布了一个极其雄心勃勃的目标:到 2025 年将其 EPYC CPU 和 Instinct GPU 加速器的能效提高 30 倍。AMD 自己也知道这是一个多么崇高的目标:该目标比典型的全行业效率提高 150%。
AMD 的新举措紧随其 2014 年至 2020 年的 20x25 计划之后,在此期间该公司的笔记本电脑芯片的能效提高了 25 倍(特别是,这包括处理器空闲和负载时的效率)。
AMD 的新计划专门针对 AI 和 HPC 工作负载,该公司的目标可能暗示其未来的硬件设计计划。例如,AMD 计划在努力实现新的功耗目标时提高性能,但它并不只是想在性能问题上投入更多的裸片面积(即更大的芯片)。相反,他们的想法是同步提高性能和每瓦性能,以实现性能和效率的提升。
与任何目标一样,AMD 必须有一种方法来衡量其实现目标的进度。鉴于该公司专注于 AI 和 HPC 工作负载的性能,AMD 选择了 FP16 或 BF16 FLOPS(具有 4k 矩阵大小的 Linpack DGEMM 内核 FLOPS),这意味着它使用通常用于 AI 训练工作负载的数据类型。
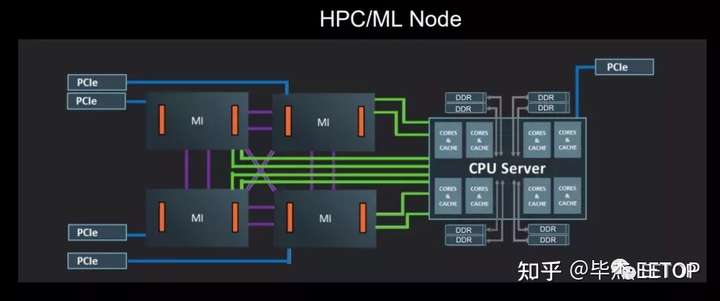
AMD 使用具有四个 MI60 GPU 和一个 EPYC CPU(未指定型号)的现有系统(计算节点)的总体性能设定了基准性能测量。这已被定义为基准“2020 系统”。AMD 将使用具有相同数量 GPU 和 CPU 的新一代服务器节点来衡量里程碑。重要的是要了解 AMD 只需为 BF16 和 FP16 数据类型添加固定功能(硬件级)加速,就可以朝着其目标迈出一大步,从而获得相对“容易”的性能和效率提升。例如,MI60 支持 FP16,但不支持 BF16。


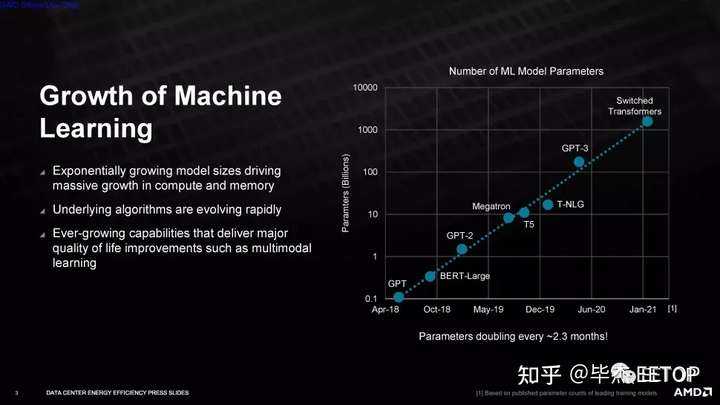
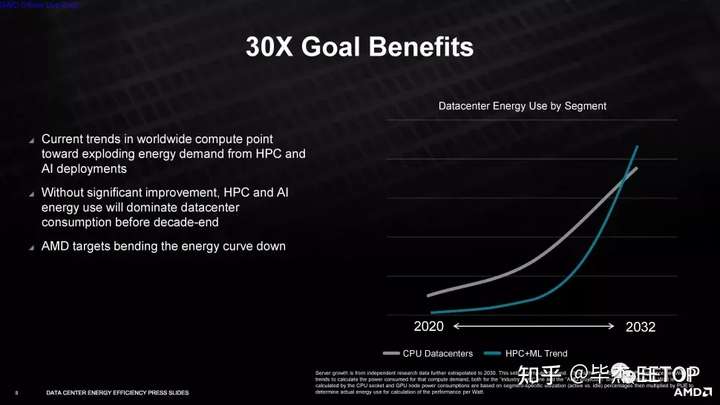
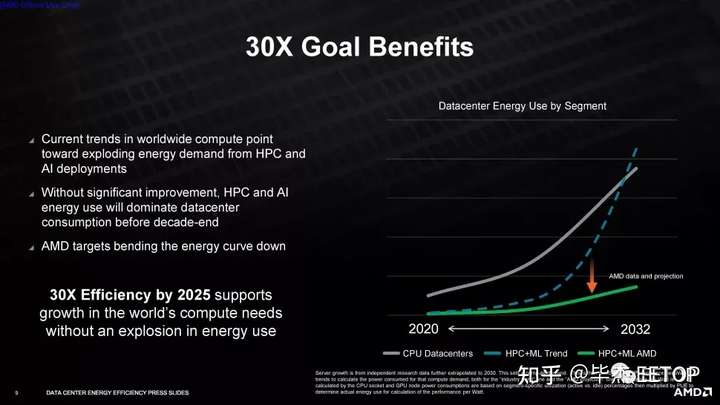
AMD 表示,它将依靠硬件和软件优化来实现其目标,但对我们在此过程中可以预期的硬件加速类型不置可否——该公司不会确认将添加固定功能的 BF16加速其 CPU 和 GPU。仅此添加就可以在目标工作负载中产生令人印象深刻的性能提升。此外,软件优化通常会导致现有硬件的大规模改进,这意味着 AMD 有多种选择来实现其目标。与 AMD 之前提高笔记本电脑效率的目标不同,该公司并未将空闲功耗测量纳入其测试方法。相反,公司将使用这些工作负载的典型利用率(约 90%)乘以数据中心PUE(电源使用效率 - 数据中心效率的衡量标准)。AMD 表示,这产生的值与每瓦功率指标非常接近,但我们还没有看到该公司用于计算的最终公式。
AMD 的能效目标是在对加速计算节点的处理需求大幅增加之后提出的,这些节点执行人工智能训练、气候预测、基因组学和大规模超级计算机模拟等功能。如果 AMD 实现其目标,该公司表示,这些系统的整体能耗将在五年内惊人地降低 97%。
AMD 执行副总裁兼首席技术官 MarkPapermaster表示:“提高处理器能效是 AMD 的长期设计优先事项,我们现在正在为使用我们的高性能 CPU 和加速器的现代计算节点设定一个新目标,用于人工智能训练和高性能计算部署。专注于这些非常重要的细分市场,以及领先公司加强环境管理的价值主张,AMD在这些领域的30倍目标比前五年的行业能效表现高出150%。”
AMD 已经在其 CPU 和 GPU 设计上探索了大量的能效改进 - 以至于 AMD Zen CPU 实际上在性能/瓦特比方面击败了英特尔。该公司还对其RDNA 2 GPU 的功耗进行了大幅改进,从Nvidia手中夺得了能源效率的桂冠。这些改进的一部分可归因于制造节点的跳跃,至少在 GPU 方面是这样。然而,随着更密集制造工艺的成本激增和研发时间的增加,AMD 显然并不仅仅指望这些。
相反,诸如3D缓存堆叠(应用于RDNA 2芯片的Infinity Cache大大降低了功耗)等技术和越来越多的效率优先的工程方法将被要求。固定功能加速和软件改进也将发挥很大作用。为了达到这一目标,AMD将寻求哪些技术,还有待观察,但令人鼓舞的是,该公司显然相信它能够在未来四年内实现这种类型的改进。























