世界最强超算芯片Fujitsu A64FX:继承于SPARC64架构的Arm超级处理器
2020-07-03 13:29:32 EETOP整体来看,无论从哪个角度观察,这应该是目前最高端的ARM 指令集兼容处理器了。
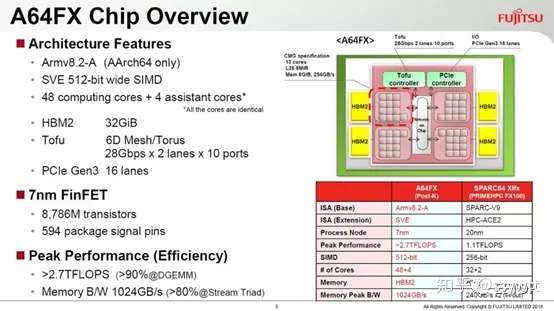
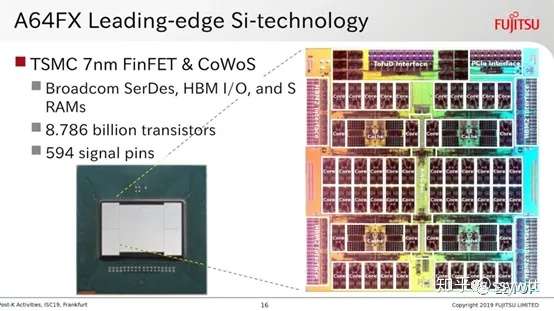
其实Fujitsu 早在2018 年夏天的处理器业界盛事IEEE HotChips 30,就公开A64FX 的技术细节(其中部分内容更在4 月就先行披露),本质算是「电脑的语言」指令集架构从SPARC-v9 转换成ARM-v8.2-A 的SPARC64fx 处理器(因衍生于高端服务器专用的SPARC64,也继承了诸多类似特色,如大型主机等级的数据可用性),采用台积电7 纳米制程生产,主存储器使用近来因高端图形芯片逐渐普及的HBM2,和运算核心由台积电的2.5D 封装CoWos 技术封装成一颗,毋需外部的存储器颗粒。
讲更精确点,Fujitsu A64FX 是「针对超级电脑量身订做的ARM 指令集系统单芯片 SoC」(System-on-Chip,SoC),其概念更可追溯于2004 年11月,一举赶下雄踞「世界最强超级电脑王座」超过两年半(2002 年3 月到2004 年11 月)地球模拟器(Earth Simulator)的IBM BlueGene/L,体积仅有容纳1,024 个运算节点和8TB 主存储器的16座机柜,反观地球模拟器动用640 个运算节点,总共5,120 颗NEC SX-6 向量处理器和10TB 主存储器,多达320 座运算机柜,彰显了追求建造速度的独到思维与异质功能融合的潜在威力。后来劳伦斯利佛摩国家实验室(LawrenceLivermore National Laboratory,LLNL)的BlueGene/L 持续扩充到104 座机柜(478TeraFlops,峰值596TeraFlops),2008 年6 月被同样出自IBM 的洛斯阿拉莫斯国家实验室( Los Alamos National Laboratory,LANL)的Roadrunner 超越,稳占Top500 首位长达3 年半之久。后者是人类史上第一台效能达1PetaFlops 的超级电脑。

那年刚好微处理器论坛(MicroprocessorForum)首次在台湾举办(新竹烟波大饭店),IBM 也在活动议程里,充分阐述BlueGene/L 的技术细节与设计理念,笔者有幸坐在台下躬逢其盛,富岳和FujitsuA64FX 则让笔者回忆起历历在目的往事。
于「日用品」堆砌超级电脑以外的另类系统单芯片路线
「世界最快的超级电脑」不但是国家科技能力的重大象征,更是科技强权之间的国力较量,根据国家的Top500 进榜数与总效能「圆饼图」,比重与趋势或多或少反映了国家的影响力。前述的富岳超级电脑,相关费用总计1,300 亿日圆,其中1,100 亿日圆由日本纳税人买单,日本政府「宣扬国威」的强烈动机,不言可喻。
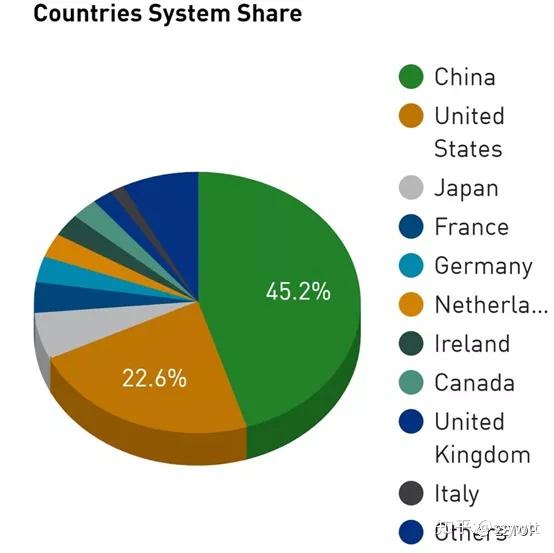
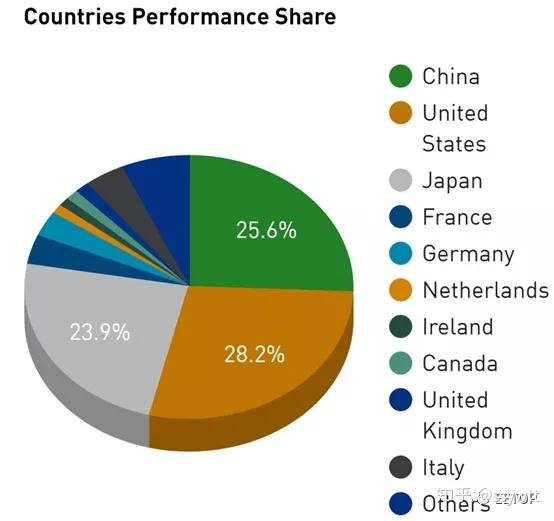
自从个人电脑与集群运算环境(Cluster)普及后,超级电脑业界逐渐从特别客制化且量少价高向量处理器、系统控制与存储器芯片,朝向采用市售的「日用品」(Commodity)或系出同源的衍生产品(如nVidia 的高阶运算用GPU),除了降低购置与维护成本,亦可进一步提高超级电脑的可靠性与可用性。
也因此,Top500 清单早是满满一整排英特尔处理器与nVidia 加速卡(与很少的AMD 产品,以及根本没有未来的英特尔Xeon Phi),偶见IBM 的高端Power 处理器与Fujitsu 的SPARC64fx。
毕竟不计成本导入特制化零件与特殊半导体制程(甚至像Cray-3和Fujitsu VPP500 还用到砷化镓这么独特的材料)的「高阶试作品」,自然远不如消费性市场随手可得的「成熟量产品」可靠。过于特殊的专属规格处理器,也限制了应用软体和开发平台的选择性,提高开发软体的时间与成本。反之,投奔「开放规格」,即可享受到更多样化的开源社群资源,并因更频繁的技术交流,而加速技术演进。
但超级电脑市场较量的重点,并不只限于帐面效能和耗电,「研发时程」和「建造速度」也同样举足轻重。这也是IBM BlueGene/L 在十多年前可在超级电脑领域独领风骚的秘密:延续现有Power处理器的研发成果,打造高度系统单芯片化的运算节点,实现更高的空间利用密度和更快的系统组装速度。FujitsuA64FX 更承袭相同的思维,并藉由台积电被众多客户千锤百炼后的成熟制程、研发资源丰富的ARM 生态圈、拜显示芯片市场之所赐而便宜可靠的HBM 存储器,青出于蓝胜于蓝,相隔近16 年,重现系统单芯片一次夺下Top500 榜首的荣景。

大处着眼,小处着手
相信熟悉超级电脑的读者或许会想起,当时那台IBM 与Livermore 实验室合作的BlueGene/L 测试机,并非彻底施工完毕的超级电脑(这让日本人颇不以为然),但在Livermore 国家实验室,确实有部分应用程式跑在上头,并打败了地球模拟器保持的纪录。问题来了,为何IBM 可以用这么快的速度(当时可是震惊世人),建好一台世上最快的超级电脑?
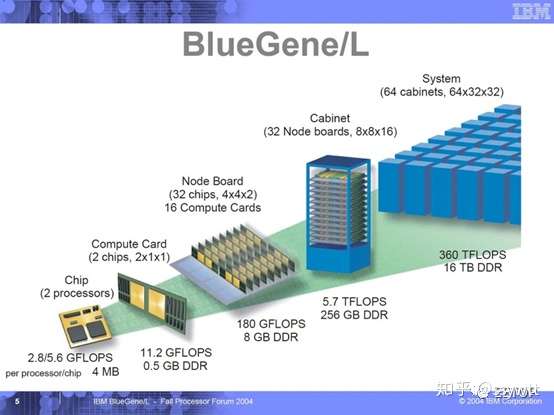
2004 年,BlueGene/L 可谓世界最大的嵌入式微处理器集合,揭示了「大处着眼,小处着手」观念,将系统单芯片的价值,从微型系统带到极大规模的超级电脑,技术核心为重新设计后的双核PowerPC 440,具低耗电量和低发热量等特点。利用诸多今日我们耳熟能详的系统单芯片特色的BlueGene/L,有以下特点:
BlueGene/L 的架构相当单纯:
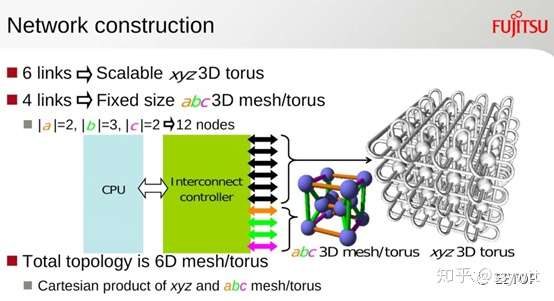
所谓的超级电脑,就是指具巨大平行运算量的系统(有别于追求顶级可靠性和极致软体相容性的商用大型主机),大多数并行处理程序,都必须在执行每个小单元,参考之前的单元计算结果,或是传送结果到其他执行单元,带来巨大的资料传输量。超级电脑的开发者几乎都将一半精力耗费在资料传输网络的设计。
BlueGene/L 系统组成极端干净,处理器芯片内建5 种功能相异的网络控制器,让不同类型的工作分而治之,只需要板子上的连接点组成整个系统,你也看不到拉来拉去的排线和到处安插的汇流排网络控制器:

为何IBM 要让BlueGene/L 同时用5 种网络架构?起因于IBM 并未为了这台「速食」超级电脑设计专用作业系统,直接修改Linux 来用,并BlueGene/L 是每颗运算节点(一颗处理器)都是独立电脑的「Multicomputer」型态,单靠3D Torus 网络不足以保证在最短时间内即时传送所有资料,特别是和计算无关的控制管理讯号,所以动用多种拓朴网络以保证面面俱到,是很正确的手段。
同场加映更夸张的设计:Sun 曾竞标美国国防部先进研究计划署(Defense Advance Research Projects Agency,DARPA)于2002 年初开始的High Productivity Computing System,日后更名为PetaFLOPS 的超级电脑计划(略早于NEC 发表地球模拟器),提出惊世骇俗的「Hero」计划,引进「Proximity Communication」研究成果,透过芯片彼此相邻的「超高速无线传输」(别怀疑),一举解决频宽延迟的瓶颈和系统组装的麻烦。很可惜这案子由IBM 和Cray 击败Sun 共同得标,无缘让世人目睹这令人啧啧称奇的世界奇观。
虽然超级电脑的可靠性要求不如商业大型主机严谨,但看在巨大资料传输量的份上,假若自己的家用个人电脑可能一年内因一次讯号错误当机,套在超级电脑就可能变成一小时一次了。
也因此,IBM 在BlueGene/L 引入许多除错技术,由小到大,从芯片(所有存储器皆受到ECC 保护以修正单位元错误)到系统(所有节点和网络都有自我错误监测,而最重要的3D Torus 网络则动用超过4 种数学除错方式以保障资料传输的正确性)。当然,低发热量的系统单芯片,也降低超级电脑因过热而不稳的可能性。
承继IBM BlueGene/L 精神的Fujitsu A64FX
这些年来,服务器大厂纷纷放弃开发自家处理器,改投向「开放系统」的怀抱,但Fujitsu 仍持之以恒研发高端处理器,如GS 系列大型主机、Unix 服务器的SPARC64、因2011年「京」 (K-Computer)超级电脑专案诞生的SPARC64fx。
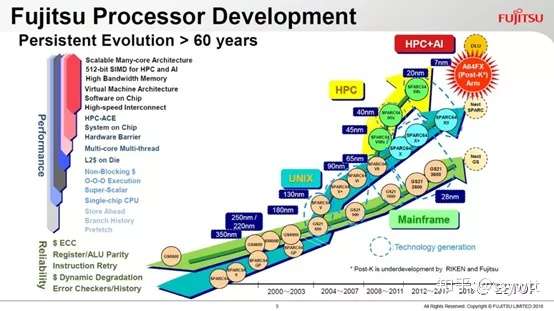
让SPARC64fx 转战ARM 指令集的A64FX,堪称三者集大成,也让ARM 指令集兼容处理器,一步登天,拥有商用大型主机(Mainframe)的高可靠度、高端服务器的高效能,与超级电脑最需要的低能耗比,身为「后京」(Post-K)时代的日系超级电脑心脏,性能目标是达到2011 年「京」的100 倍。富岳抢下Top500 榜首就是成果,且计划进度还比表订的2021 年量产出货提前甚多。
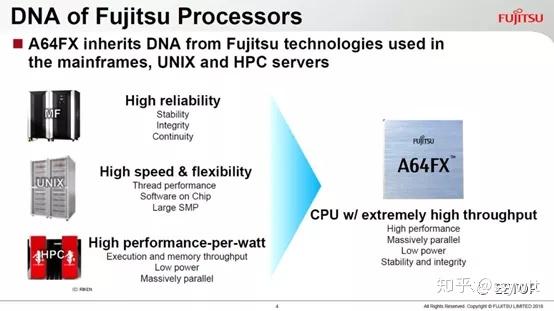
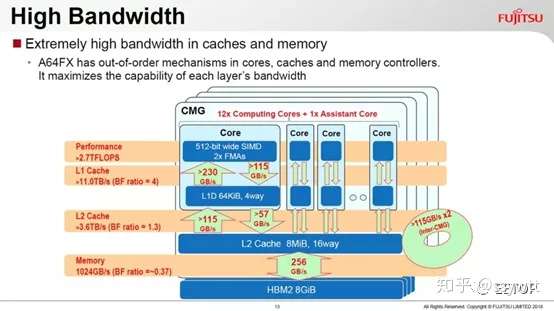
A64FX 主要特性如下:
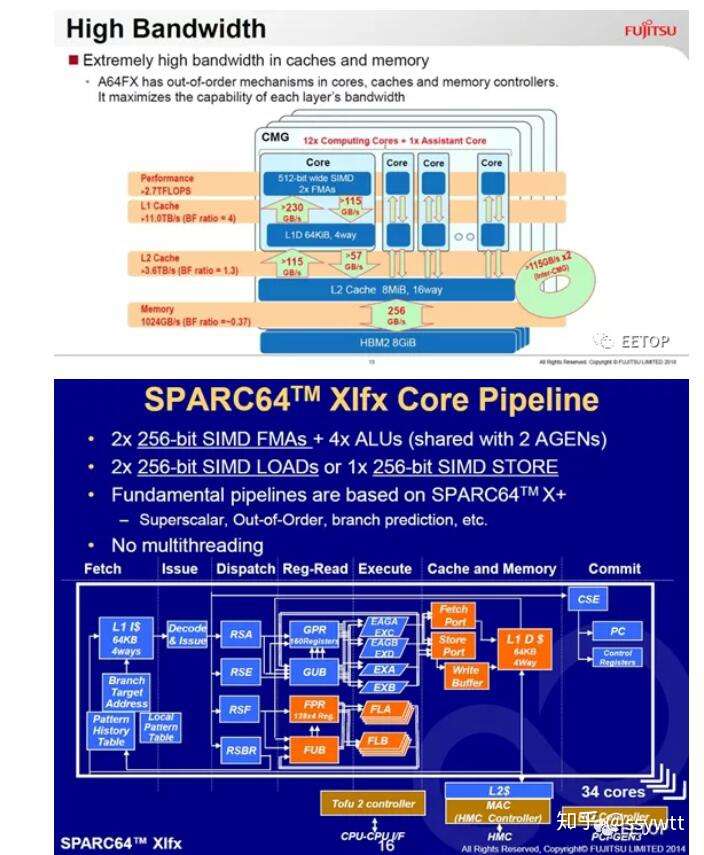
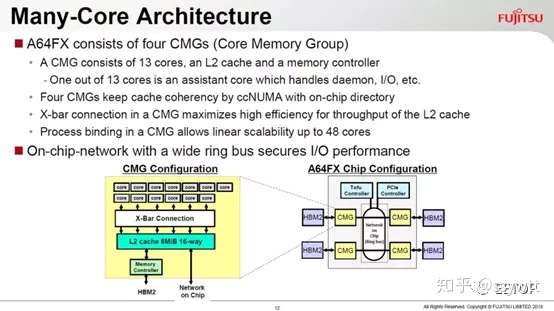
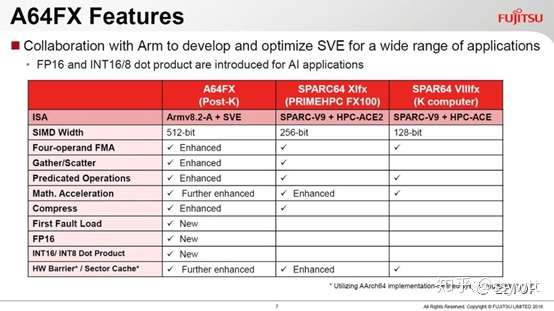
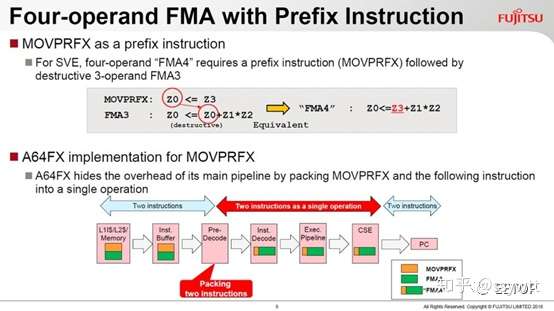
ARM 的SVE 不仅「比英特尔AVX-512 更富有向量电脑的传统风味」,也有个有趣的MOVPRFX 指令,用来弥补ARM 迈进64 位元后,为了提供32 个暂存器(需要5 位元指定一个暂存器,4 个就是20 位元)牺牲掉的FMA4 四运算元浮点乘积和(A×B+C=D)。一旦执行三运算元的FMA(A×B+C=C),会覆盖掉一个暂存器的原始内容。
MOVPRFX 指令可预先经由前置码(Prefix),「更名」运算目标暂存器,以保留其内容。而A64FX 的内部执行单元则会将接连的MOVPRFX 和FMA3 两个指令合而为一,变相实作FMA4,掩盖执行两个指令的额外延迟。


「热情拥抱现成资源」的弦外之音
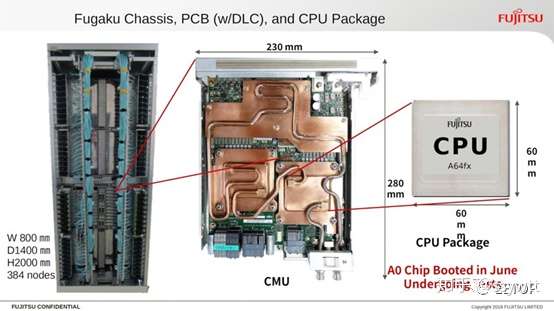
Fujitsu 和理化学研究所在2019 年4 月15 日签订制造出货安装合约,11月富岳试作机拿下Green500 第一名,12 月2 日就开始出货6 个机柜框体,全数396个在2020 年5 月13 日全部搬入理化学研究所,速度真的很快,当年IBM BlueGene/L 的「速食」风格,在Fujitsu A64FX 也一览无遗。
况且,Fujitsu 还享用那时IBM 还体验不到的「完整IP 授权、最佳化电子辅助设计工具与相关函式库、专业晶圆代工」三位一体的成熟产业生态体系,大量引用「现成资源」加速产品研发与验证,降低成本,不限硬体,一并拥抱蓬勃发展中的ARM 软体资源,在「沿用市售标准品」和「拼死硬干特规货」中取得平衡点。这是Fujitsu在高效能运算处理器的「语言」,放弃SPARC 转向ARM 背后最重要的弦外之音。
最后,顺带一提,如果台积电继续维持制程优势,英特尔真的还有机会追上来吗(官方预定2021 年7 纳米、2023 年5 纳米、2025 年3 纳米、2027 年2 纳米、2029年1.4 纳米)?还是昔日傲视世界的半导体制造能力,将就此遭到毁灭性的打击?值得拭目以待。