ARM推出下一代旗舰芯片架构,GPU提升60%,「NPU」即将上线
2019-05-29 09:02:46 机器之心ARM 表示,新的芯片展示了该公司在 5G 融合、物联网、人工智能(AI)与自动驾驶领域的投入。

Arm IP 产品事业群总裁 Rene Haas 在发布会上。
Cortex-A77:制程不变,性能提升 20%
对 Arm 自己的 CPU 设计来说,2018 年是个不错的年份。去年 5 月,我们看到了 Cortex-A76 的发布,以及后续的麒麟 980 和骁龙 855 芯片。从人们购买的反应就可以看出来——这代芯片令人印象深刻,而 Arm 成功实现了其在性能、效率和领域方面的所有承诺,为 2019 年的大多数旗舰手机提供了出色的芯片和设备。
今年,Arm 跟进了另一项技术,Cortex-A77——Cortex-A76 的继任者。这一代 CPU 将是对去年主要微架构的直接进化,代表了 Arm 全新 Austin 内核系列的第二个实例。
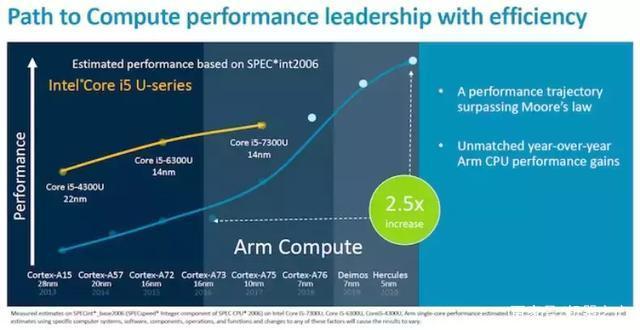
Cortex-A77 不仅适用于手机,也可用作笔记本处理器,Arm 称其性能已经超越 14nm 制程的英特尔酷睿 i5-7300U。
代号 Deimos
新的芯片架构 Cortex-A77 代号为 Deimos。它将 Cortex-A76 终止的地方作为起点,并遵循 Arm 的计划轨迹,即每一代新的 Austin 系列 CPU 性能都能持续提升 20-25% 的 CAGR。
说到这里,就有必要提一下 Cortex-A76 的性能了。

A76 对 Arm 及其授权厂商来说无疑是一款非常成功的内核。全新微架构和台积电 7nm 制程工艺的结合,带来了业内有史以来最大的性能和效率提升。结果就是麒麟 980 和骁龙 855 相对于各自的上一代手机芯片都有很大的性能飞跃。
虽然 A76 表现不错,但竞争对手也没有停滞不前。三星的 Exynos(猎户座)处理器相比其上一代产品就有很大提升,制程是 8 纳米。而真正的对手苹果当前的 A11 和 A12 架构在性能和效率方面仍然遥遥领先,Arm 与它的差距大概是两代微架构。

图片来自 ChipRebel
Cortex-A77 概述
Cortex-A77 直接继任了微架构 A76 意味着新的内核基本与先前的特性保持一致。Arm 表示,内核是为厂商设计的,他们无需太费力就可以轻松升级芯片 IP。

实际上,这意味着 A77 与其前身 A76 在架构上是一致的,仍然以 ARMv8.2 为 CPU 内核,并且与 DSU(DynamIQ Shared Unit)集群内部的 Cortex-A55 小 CPU 配对。
A77 的缓存大小等基本配置特性与前身也没有太大区别:仍然是 64KB 的 L1 指令和数据缓存,以及 256 或 512KB 的 L2 缓存。有趣的是,Arm 的确为基础设施 Neoverse N1 CPU 内核(源自 A76)设计了 1MB L2 缓存选项,但选择保留客户端(移动)CPU IP 的较小配置选项。
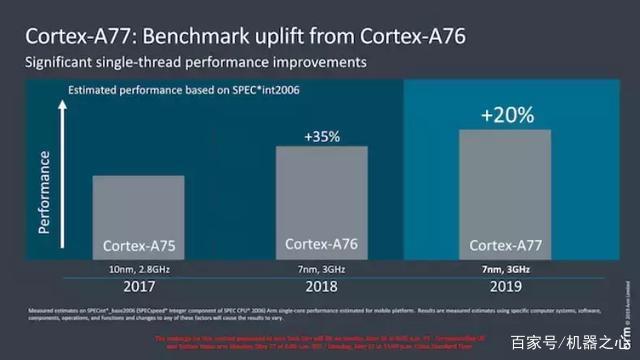
作为 A76 的进化版,不论是从微架构还是从绝对性能的角度来看,A77 的性能提升都没有预期中那样令人惊艳。
A77 将还是采用 7 纳米制程,Arm 宣布它的峰值目标频率与前身一样为 3GHz。自然而然地,由于频率不会有太大变化,这意味内核的 20% 性能提升只能归因于 IP 的微架构变化。
为了实现 IPC(Instructions per clock) 增益,Arm 重新设计了微架构并引入了巧妙的新特性,总体上增强了 CPU IP,从而实现了更宽、更高性能的设计。
Mali-G77:全新架构,机器学习性能提升 60%
在 2019 年,全球游戏市场产值将高达近 1500 亿美元,这将是全球最大营收的市场之一。ARM 昨天推出的新一代移动端 GPU 将承载其中与日俱增的计算需求。
Mali-G77 采用了全新的 Valhall 架构,这是继上代 Bifronst 架构发布三年之后的又一次重大升级。在性能上,与上一代的 Mali-G76 GPU 相比,Mali-G77 具有近 40% 的性能提升。同时 Mali-G77 还在关键的微构架上进行强化,包括引擎、texture pipes 和 load store caches,并将功耗效率以及性能密度均提升了 30%。
除此之外,Mali-G77 同时带来 60% 的机器学习性能提升,显著提升推理与神经网络性能,以支持更多的人工智能应用。新的芯片设计将为开发人员提供更大的发挥空间,为移动 APP 生态催生出更多的新形式交互体验。
Bifrost 架构的最后一次迭代——Mali-G76,对 Arm 来说是一次重大的飞跃,其 IP 在很大程度上解决了前身的一些关键问题,为 Exynos 9820 和麒麟 980 芯片组带来了相对较好的结果。
但是,Arm 在迎头追赶并努力解决 Bifrost 问题时,其对手也没有闲着。高通的 Adreno GPU 架构已经引领移动领域好几年了。尽管今年的 Adreno 640 没有带来令人印象深刻的进步,但在性能、效率和密度方面,它仍然领先 Arm。并且,苹果 A12 的 GPU 在性能、效率方面带来的绝对是一个重大飞跃,即使是高通最好的 GPU 也与之相去甚远,更不要说 Arm 的了。

Valhall GPU 的第一次迭代即是 Mali-G77,它实现了一些架构上和微架构的改进。
Arm 承诺在能效和面积密度(在 ISO 性能和制程方面)方面会有 30% 的增益,而 GPU 上机器学习推理工作负载的性能会提升 60%。
更有趣的是,Arm 表示在即将到来的 2019 年底和 2020 年,SoC 将预计比 2019 年的设备性能提升 40%。下一代 SoC 将只有微小的制程节点改进,所以这里说的 40% 增益将主要来自 Mali-G77 GPU 在架构和微架构上的飞跃。
人工智能正在成为便携设备中不可或缺的组成部分,拍照中的场景识别、增强现实中的物体识别都需要特殊的算力。面对目前不断出现的深度学习手机应用,ARM 一直在主推「异构计算」方式:使用手机芯片中的 CPU、GPU 和 ISP 协同工作承担相应任务。
不过随着华为麒麟、苹果 A 系列芯片的成功,ARM 也在着手开发自己的机器学习 IP。2018 年 2 月,这家公司公布了针对人工智能的计算芯片 Project Trillium 项目。本次 ARM 透露了自家「NPU」(神经网络处理单元)芯片的能力。
ARM 表示,其最新的 NPU 可与 CPU 实现协同计算,提供高达两倍的能效(5 TOPs/W),存储器压缩能力提升三倍。在与开源框架 ARM NN 共同使用的情况下,ARM NPU 的八核版本可以提供高达 32TOP/s 的算力。
ARM 的神经网络芯片设计作为一个可选项目,即使客户选择的 A77 设计中不含有该芯片,其手机仍然可以通过 CPU、GPU 等处理器完成机器学习计算。Haas 表示,ARM 的优化工作已大幅提升了深度学习框架的性能,特别是 TensorFlow。
在活动中,ARM 高管,产品事业群总裁 Rene Haas 也被问及了与华为合作的问题,他表示:目前与华为终止合作仍存在很多变数,目前无法透露太多细节。
ARM 提供芯片架构设计,具体实现还需要各家厂商的努力。在 2020 年,我们或许就可以看到采用新一代设计处理器的手机上市了。
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!

EETOP 官方微信

创芯大讲堂 在线教育

创芯老字号 半导体快讯
相关文章
 0
0
















