大话众核心处理器体系结构
2015-11-03 09:46:28 大话存储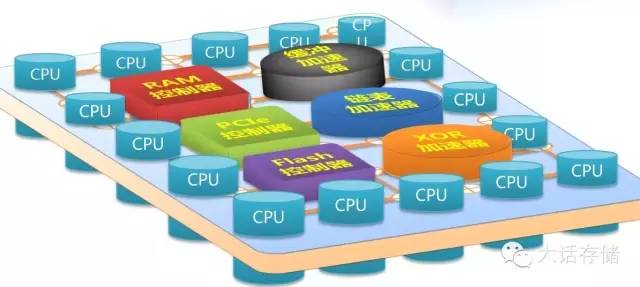
尘世浮华迷人眼,梦中情境亦非真。朝若闻道夕可死,世间何处有高人?《闻道》,by 冬瓜哥。
前不久,冬瓜哥注意到了如下新闻,
俩毛头小子获得125万美金投资,号称其设计的CPU“颠覆”目前的体系结构,保持性能持平的前提下将功耗降低10~25倍。冬瓜哥略感到一股“互联网+”的浮躁风潮,终于侵害到最后一片领地了。于是,冬瓜哥就想写一篇关于众核心CPU体系结构的布道文章了。
【主线1】从SMP/NUMA说起
多CPU在早期是通过一个共享总线比如FSB连接在一起,同样挂接在FSB上还有内存控制器,桥控制器等,这种多个CPU共享访问集中的RAM的架构成为SymmetricMulti Processor(SMP)架构,或者UMA(Uniform Memory Access)架构。如图1所示。
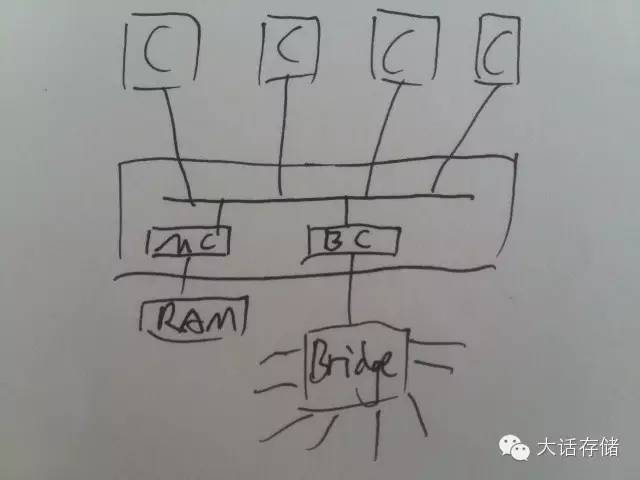
图1
后来共享总线改为了规格更高的交换式架构,所有CPU内部的关键功能部件全部放到一个Ring上,相当于地铁环线一样来运送数据,而多个环线之间,再使用交换式架构的分布式交换矩阵连接在一起。所以,CPU访问自身环线上的内存控制器,速度很快,而访问位于其他环线的MC,则需要通过分布式交换矩阵,整个内存空间还是多CPU共享而且可以直接寻址的,但是访问距离近的MC,速度快时延低,访问远处的则速度慢时延高,所以为None Uniform Memory Access(NUMA)架构,如图2所示。交换式架构可以扩展到更多CPU和RAM,比如32路Intel x86的服务器马上就要出来了。
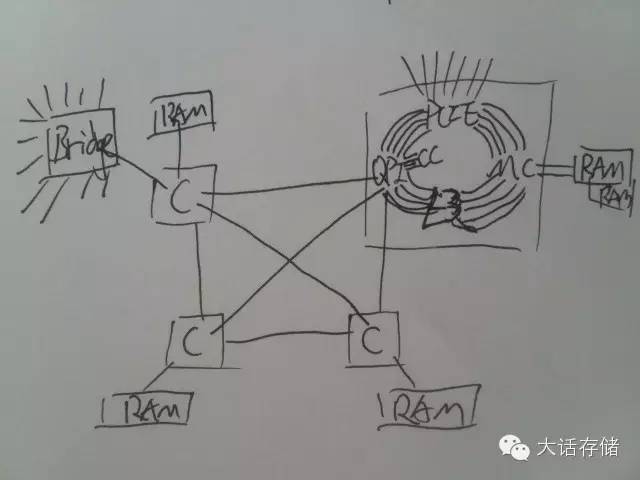
图2
值得一提的是,在这个交换矩阵中,不一定非得用CPU内部的环线来挂内存,可以用任何方式将内存接入这个矩阵,也可以在这个交换矩阵的任何地方放置一个或者多个MC,挂一堆内存,然后用MC-QPI桥片接入QPI交换矩阵即可。典型的代表就是IBM x3950 x6产品系列中有个专门的1U箱子,里面全是内存。如图3所示。

图3
【主线2】AMP/异构计算
上述的体系中,所有CPU都是同样的结构,OS启动后,所有CPU地位都是相同的,可以调度任何线程到任何核心上运行,这叫做同构计算,同构的专业英文术语叫做homogeneous。而还有一种称为Heterogeneous,意即异构。异构计算的一个典型例子就是超算,有些超算系统采用了GPU或者Intel Phi这类结构不太相同的CPU,来辅助主CPU的运算,其被称为协处理器。然而,虽然是“协助”,其实协处理器在某些特殊结算场景下性能会几倍甚至十几倍于通用CPU。运行3D游戏就是个例子,显卡上的GPU是协处理器,主CPU负责提供GPU充足的数据进行计算/渲染,GPU中数以千计的微型核心并行进行专用的计算,方能渲染出效果非凡的实时3D动画。所以,异构计算,说白了,就是一个元帅,带着几个身强力壮的将军打仗,元帅只管调度和发号施令,将军则执行具体的军事任务,上刀山下火海。这种体系被称为Asymmetric Multi Processor(AMP)。
【支线】“能模拟地球”的Cell B.E处理器
IBM的Cell B.E处理器就是一款典型单芯片的片上AMP系统。尚未发布之前,IBM宣称其性能爆表,秒杀同时代Intel CPU。后来不知道怎么回事,以讹传讹,有人说Cell处理器可以承担模拟整个地球的运算量,后“模拟地球”便指代Cell处理器,后来Cell处理器由于编程麻烦,已停止开发。但这不妨碍我们研究一下它,从中吸取一些营养。
其在同一颗芯片中集成了8个支持128位SIMD的专用RISC核心,以及一颗PowerPC通用核心,再加上内存控制器、IO控制器,所有部件连接在一个Ring环线上。如图4所示。
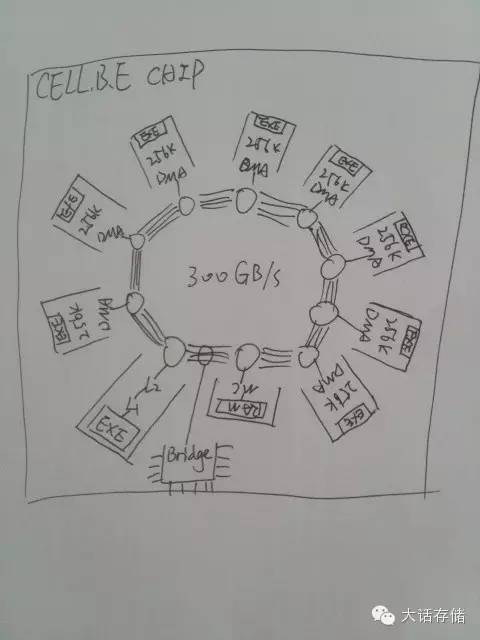
图4
操作系统,或者说主控程序,运行在PowerPC上,将任务数据和描述放到RAM中某个Queue,然后多个SIMD专用核心从这里取走任务、处理然后将结果写回RAM,中断PowerPC,处理、输出。SIMD专用核心上运行自己的程序,这些程序与PowerPC上运行的程序没有直接关系,这些程序各自看到各自的地址空间,也就是256KB的scratchpad ram,就是SRAM,和CPU的L1/2/3 Cache使用相同介质,只不过通用CPU的Cache是不可直接被程序寻址的,程序看不到Cache空间,而Cell处理器的SIMD核上的256KB Cache是可以直接寻址的,程序只能看到256KB的地址空间,代码+数据不可超出256KB,所以这个核心的地址位数就可以是log2 256K。外部的DDR RAM并不被纳入地址空间,而是像访问硬盘一样,将地址封装到消息中,通过DMA引擎读入到256KB的ScratchpadSRAM中处理,然后写回。所以,外部DDR RAM不能直接寻址,代码得先调用操作DMA引擎的库来将数据载入本地256K SRAM。而传统的通用CPU,这个过程完全不用软件参与,软件被编译成机器码之后,机器码的操作地址直接可以是外部RAM的地址,而由硬件来负责直接存取外部RAM,所以,编写通用CPU代码的程序员,面对这种AMP体系,就感觉头疼了。
比如,通用CPU在RAM和取值、LS单元之间会有一层Cache,并由硬件来管理,而Cell处理器内部的SIMD核并没有管理Cache的硬件,实际上也并没有Cache,其SRAM相当于RAM,其RAM相当于硬盘。代码想要实现Cache预读等缓冲操作,就需要自己开辟一块空间作为Cache,自己管理预读、写回等,全软件操作,这让软件开发者苦不堪言。Cell处理器率先被用在了索尼PS3游戏机中,这估计害苦了索尼机的游戏开发商了,不过即便如此,仍有顽皮狗这种顶尖团队开发出《神秘海域1,2,3》系列和《美国末日》这种索尼平台的经典游戏。最终,Cell停止开发。目前最新的游戏机比如PS4和XB1,都是x86体系的CPU+GPU,或者将二者做成一个芯片并以更高速的总线将CPU和GPU片内连接,称之为APU。PS4平台明年初会有超级大作《神秘海域4》出炉,冬瓜哥一直决定买台PS4玩一玩,但是一直没有时间来玩,也不知道什么时候能闲下来。
SIMD核心由于节省了这些硬件资源,缩小了电路面积,可以在一个芯片上设计更多数量的核心,对于并行计算场景有较大的加速效果。而其对于一些不可并行计算的场景,需要采用另一种任务调度方式,也可以达到较好的加速效果。详见下文。
【主线2】NoC--众核心处理器的关键
核心越来越多,如何来将这么多CPU核心之间、以及核心与RAM之间、以及核心与其他IO控制器之间,连接起来,成了一门独立学科——Network on Chip(NoC)。上文中所述的Cell处理器,其NoC就是Ring环线。如果是几百个核心,比如256核心/节点,利用Ring就不合适了,这个Ring网络的“半径”就是128,意即任何一个节点发出的消息,最差情况下要经过128次传递才会到达目标节点,时延太高,无法消受。所以,业界通常使用2D FullMesh网络来连接如此多的部件。如图5所示。
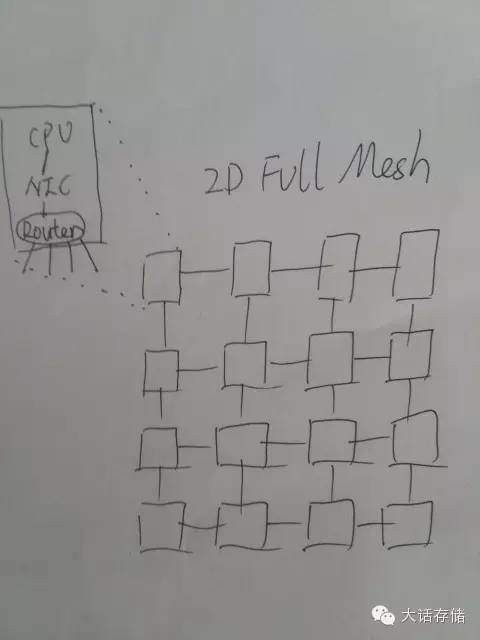
图5
可以看到,每个核心通过NIC连接到一个路由器,路由器出4外部口,与其他CPU核心连接。这里所谓“NIC”只不过是一个网络控制器,其连同Router被做在同一片电路模块中,与CPU通过某种总线连接起来。当然,这些网络并不是以太网等我们熟知的网络,因为外部网络很复杂,做了很多设计,NoC由于在芯片内部,可以做很多舍弃和专用设计,所以及其精简和高效,电路面积很小。这种网络的路由方式,基本都是被写死的静态路由,也就是哪个ID在哪,从哪个口走,都被初始化代码定死,这样就不需要动态路由协议了,削减了不必要的电路。
NoC有很多链接方式,比如下面这种就被称为3D Torus网络,如图6所示。超算领域也需要将大量CPU连接到一起,也是使用这种方式,只不过超算领域的网络拓扑更多样,比如Fat Tree,HyperCube,FullMesh,Torus,Butter,以及各组合。所以,把众核心芯片称为片上HPC,也不足为过。
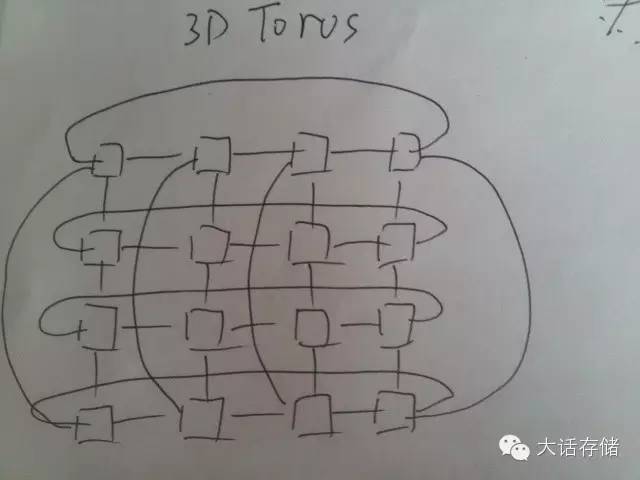
图6
在NoC,每个器件,比如CPU核心、DDR控制器等,都有各自的节点ID,如果访问的是DDR控制器后面的RAM,则程序需要将RAM地址封装到消息中,并附上DDR控制器的节点ID,发送到NIC进行路由。
【支线】众核共享内存—难求也!
有些众核心不支持直接寻址DDRRAM,这就意味着多核心上的程序不能简单的共享内存,比如我声明某个变量在A地址,这个地址只是该程序所在核心能看到的本地地址,其他核心访问不了另外核心的这个地址,所以,多个核心上的程序,就不能是一体的,而必须是独立的,想交换数据的话,就得从外部DDR RAM走,而且自行控制加锁和一致性,硬件不管,这又增加了编程的复杂度。
把DDR RAM当做IO方式来用,是有设计上的考量的,设计师完全可以加宽地址译码器,并增加硬件微控制器/译码器将地址请求转换成NoC消息去访存。设计师之所以将RAM搞成了IO,其原因有两个,第一是节省这些译码硬件资源;第二则是提升吞吐量。第二点原因看上去不太应该,将直接访存搞成IO还能提升吞吐量?这可能与很多思维背道而驰。理解这个问题需要的逼格比较高了。众核心CPU核心内的流水线数量、级数都不会租的很多,不像通用CPU比如Power8系列一次直接发出8个LS请求,16条流水线并发。众核心由于一个芯片上要做数百个核心,其只能降低核心内部控制逻辑的功能和复杂度,所以,其LS单元队列深度很低,几乎就是同步操作了,LS数据未返回之前,整个流水线就被stall了,严重影响吞吐量,而NoC链路相比QPI/HT等要慢得多,跳数也多,时延也就高,如果不用流水线高队列深度异步请求的话,吞吐量根本上不来。所以,要想异步请求,好办,那干脆就别直接用LS访存了,代码直接调用API将请求发出到NoC控制器封装成消息发出去,这样的话,在软件层面实现异步IO,将底层队列压满后,吞吐量方能上的来,但是大大增加了软件的复杂度,处理数据之前,先批量将数据读入本地内存,然后在本地处理,而不是处理一条数据访存一次。传统CPU上运行的程序,可以肆无忌惮的任性,丝毫不关心内存放在哪,怎么样才最快。而众核心上的程序,就得精打细算了,所以,众核心基本被广泛用于专用场景,比如防火墙、流处理、视频处理等。大数据分析其实也很有应用潜力。
实际中,有些产品是同时支持走IO和直接寻址来访问DDR RAM的,程序可以自行选择,这一点就比较好了。
所谓NP,network processor,多半使用了这种众核心架构,因为要达到充分的并行性,核心数越多,并行度越大。然而,通用CPU可以通过不断的线程切换,也实现类似的Concurrency,所以现在一些个所谓SDN方案,软件交换机,软件路由器,看着也像那么回事,比如Intel使用DPDK库来加速数据从网卡传递到内存的过程,至于收到包之后的处理,看上去通用CPU目前的性能,也还可以。但是通用平台的一个劣势就是其不提供外围多样的应加速器件,而专用的处理器可以集成一堆的应加速部件。当然,随着工艺提升,Intel也正愁到底往芯片里塞点什么进去好呢?之前有些东西,塞进去过,又拿出来,又塞进去,愁人啊,干脆塞个FPGA进去算逑了,想弄点什么加速逻辑进去,换个固件就完了,当然,这是后话了。
【支线】PMC-Sierra公司代号Princeton的Flash控制器
凡是追求高并行度的,大量工序协作的专用场景,都可以用众核心处理器。PMC-Sierra公司的Flash控制器就是一款16核心众核处理器,采用2D Full Mesh NoC,16个核心连同PCIE控制器、Flash通道控制器、DDR控制器、多种硬加速器一起分布在该NoC上,采用消息机制传递数据,支持以IO方式访问RAM,也支持直接将外部RAM空间映射到本地地址空间访问,难能可贵。至于其固件是如何在16个核心上分配的,冬瓜哥就不继续展开了。冬瓜哥画了一张图如下,如图7所示。

图7
【主线3】俩小子搞出来的NeoProcessor
被冬瓜哥打通了任督二脉之后,我们再回过头来看一下最近这条新闻。两个“毛头小子”(图8)弄出一个所谓“新体系结构”,详见www.rexcomputing.com。
![]()

图8
声称“In doing so, we are able to deliver a 10 to 25x increase in energyefficiency for the same performance level compared to existing GPU and CPUsystems”,这句话,冬瓜哥可以负责任的讲,三个字,大忽悠。他可以说在某些专用场景下,超越目前的GPU和CPU,但是这句话说得太满了,根本是不可能。只有那些想吸引投资的人,才会这么去忽悠,冬瓜哥认为这两位兄弟,是用了所谓互联网或者带个加号的思维,来整CPU,投资人们眼前一亮,我尼玛,CPU也可以是互联网CPU啊,CPU也可以玩一把嘛。“通用”处理器,这个定位冬瓜哥感觉一开始就错了。某些应用并行度很差,256个core根本没用,这种应用,就算软件更改之后跑在这种众核心上,基本就是扯淡。
如图所示,冬瓜哥并不清楚这俩小子到底有没有用过Tilera的芯片,如果真的是“design from bottom”,那应该趁早打住重新审视一下老大哥Tilera今天是个什么状况。图9所示为这个Neo Processor的体系结构,乍一看与Tilera别无二致。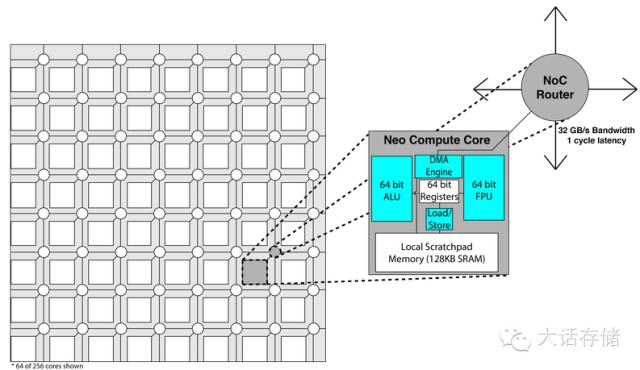
图9
如果说这俩天才少年是想在软件方面简化开发的话,那无可厚非,如下图10所示。其提供了一些基础库,避免程序自行去管理内存/Cache。但是这并不是什么颠覆性的东西。
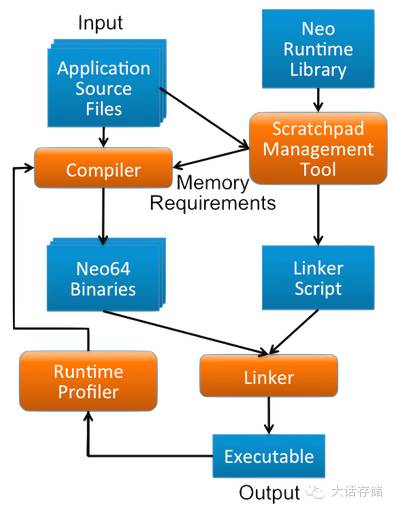
图10
“The Neo architecture addresses these problems by removingunnecessarycomplexity from hardware, resulting in smaller chip area and lesspowerconsumption, instead providing similar functionality more efficiently in arichsoftware toolchain.” “Wehave rethought computing architecture from theground up to design our Neo chip,featuring a completely new core design includingsoftware managed scratchpadmemory, 256 cores per chip, a mesh network-on-chipand a high bandwidthchip-to-chip interconnect.”
但愿这两位天才少年在说上面这句话之前,已经全面考察了他们老前辈Cell B.E和Tilera的光辉事迹,他们是如何从一开始的闪光耀眼,走到最后人老珠黄的。不过,125万美金,对于墙街来讲九牛一毛,但可玩玩无妨,万一玩出名堂来了呢,对吧。所以,这则新闻,外行看看热闹罢了。
【主线4】众核心处理器的任务调度
非对称式异构协作
在众核心上调度任务,有两种方式,一种是将同一个任务分层多步,每个核心执行其中一步,执行结果传递给下一个核心继续处理下一步,流水线化之后,整体吞吐量可以上的来。比如防火墙,处理一个网络数据包,需要经过多道工序,比如校验、解析地址、排查ACL、匹配正则表达式等等等等,每个核心可以只做一件事,比如匹配ACL(可能使用到硬加速),一个包进来匹配完了走人,再下一个包,这样,每个核心都全速运转,只要匹配好每一步的速度。上述这种协作处理方式可以称之为非对称式异构协作,也就是每个核心处理不同数据的同一个子工序步骤,这也是现实中的工业生产流水线的常规做法。
对称式同构协作
然而,有些业务,并不适合这样处理,比如,3D图像渲染时光线追踪的计算,其计算过程中并不是我算完了扔给你我就不管了,而可能会回来追溯你让你提供更多信息,这就麻烦大了,多个子工序之间有很强的关联性,需要不断的沟通交互数据,这一交互数据,就得走外部DDR RAM,此时时延大增,那么CPU只能原地空转。面对这种场景,就需要切换到另一种调度方式上——对称式同构协作。比如光纤追踪计算,可以将要处理的图像分割成多个切片,由总控程序将任务结构描述和数据放置在DDR RAM中,形成一个队列,然后众核心们从队列中提取任务执行,并保证同步,也就是需要对队列加锁并标记,防止多个核心同时取到同一份任务的脑裂场景。多个核心并行处理完成每个切片的所有工序,工序之间有依赖没有关系,因为是在同一个核心之内依赖,不牵扯到核心之间的数据交换,不会导致等待,最后由总控程序将结果汇总输出。在这种调度方式下,每个核心之间完全不相关,各干各的。典型的比如数据搜索,1GB的数据,每个核心载入其中的一部分,然后搜,各搜各的,这也是Mapreduce的思想。
对于那些并发度本来就很少的业务,或者根本不可并发的业务,或者不可切分为多个独立处理单元的数据,就得使用非对称式异构协作了。这类业务如果是运行在普通通用CPU上,就得考虑将其流水线化工序化,并将每道工序映射为一个线程,靠CPU的线程切换完成轮转,将流水线运作起来。





















