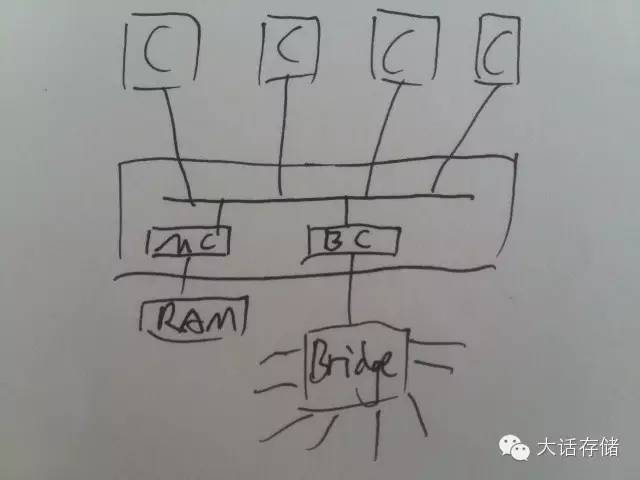
申威26010处理器每片处理器包含4个核心,片上的4个核心通过片上网络互联,并通过PCI-E 3.0对外连接,每个核心拥有独立的128位DDR3控制器连接到8GB DDR3-2133内存,这样4个核心一共拥有32GB的DDR3内存。


从这里可以看出SW26010实际上类似于用胶水把4个独立的处理器粘在了一起,整合到了一个芯片里面,但是每个核心还是可以独立工作,而且拥有独立的128bit 8GB内存。这样单个核心的内存带宽达到了34GB/s,整个处理器达到了136GB/s,这样设计最大的好处就是每个核心的带宽是完全独享的,缺点是空闲核心的带宽无法共享给其他核心。
其中每个核心包含一个主
处理器(MPE)和一个8*8的计算单元阵列(CPEs),主
处理器是一个64位的
RISC架构核心,用来跑操作系统,并且支持264位的矢量指令集,拥有32KB的L1指令缓存和32KB的L1数据缓存(总共64KB L1 cache),和256KB L2 Cache,应该说这样的缓存配置并不算大,应该是为了节约
芯片面积考虑,4个核心的主
处理器加起来一共有256KB L1 cache和1MB L2 cache。
计算单元阵列(CPEs)是一个由64个简化的62bit
处理器(不是常见的64bit)组成,每个
处理器只有16KB的L1指令缓存和64KB本地储存,没有L1数据缓存,并且和主
处理器一样支持264位的矢量指令集,单片
处理器拥有一共256个这样的计算单元。
于是加上4个主处理器,单片处理器一共拥有260个处理器核心。

神威·太湖之光的每个处理器卡有两片SW26010处理器,和一共64GB内存,长得像这样,每个处理器算一个计算节点,这样一块处理器卡和intel xeon phi协处理器卡类似,只是intel这样一块计算卡只有区区60个核心,而且不能独立工作,还需要另外购买一个独立的xeon主机作为管理处理器使用。而SW26010处理器集成了管理处理器,可以独立工作,并且单个处理器卡拥有高达520个处理器核心。

对比一下intel xeon phi计算系统的结构:

KNC Card就是一块intelXeon Phi协处理器卡,协处理器卡通过PCIE-X16和主处理器相连,其实看上去就像是一台PC上面插着好几块显卡。这样一台PC构成一个计算节点。
对比SW26010
处理器的方案,单个节点来看,一块SW26010的核心数量和一台带有4块xeon phi计算卡的功能相当。Intel方案的麻烦在于,这样一个计算节点的功耗和体积远远大于SW26010,而且
intel主
处理器内存和协
处理器卡的内存是分离的,需要先将要处理的数据通过PCI-E x16传输至计算卡内存,然后计算卡才能计算,最后将结果通过PCI-E x16读回主
处理器,这样一来一回的性能损失很多时候远大于计算卡带来的好处。
SW26010的主
处理器和协
处理器的内存是共享的,这样无需来回从协
处理器倒腾数据,而且可以实现类似
AMD APU的统一内存寻址,大幅度提高了协
处理器的使用效率,从这点来说SW26010的方案是优于
intel方案的。
从单个核心对比来看,Intel的phi协
处理器据说是基于最早的奔腾x86方案改进而成,多了一个512位的矢量
处理器,而SW26010只有264位的矢量
处理器,phi拥有32KB的L1指令缓存,32KB的L1数据缓存和512KB的L2 缓存,对比SW26010的协
处理器只有16KB的L1指令缓存和64KB的本地存储,而且
intel的phi核心可以支持4个物理线程,也就是超线程技术,单纯从技术来讲,
intel的phi
处理器拿出来单挑应该可以吊打单独的SW26010的计算核心。
理论性能可以看出,单个
intel的phi
处理器是高于SW26010的计算核心,得益于超宽的512位矢量
处理器(VPU),
intel phi上的
处理器每个时钟可以执行16个单精度运算或8个双精度计算,而SW26010上的计算核心只有一半的宽度,所以最多也就8个单精度和4个双精度,不过SW26010的核心频率是1.4
5GHz,要比
intel phi的1.3GHz稍高,但是这样也很难追平
intel的单个核心的理论性能优势。
但是光比理论峰值性能是没有什么意义的,SW26010的VPU虽然比
intel phi的宽度小,但是264bit的宽度而不是256bit的宽度可以提供比
intel的单双精度浮点更高的计算精度,单精度浮点可以比
intel的高一倍,而双精度可以高4倍,这在科学计算中是能够获得更大的优势,而且
intel的512bit宽度的矢量运算需要更多的数据来填饱它,加上需要用PCI-E传输数据的瓶颈,大部分时候也只能挨饿,而SW26010可以直接访问主存,因此在实际使用效率上不见得就会比
intel phi低多少,并且某些应用场合甚至可能大幅度超过
intel。
而且最重要的是,SW26010这样的设计,大幅度降低了系统复杂度,单个计算节点只需要一片SW26010,而
intel就很杯具的需要一整台机架服务器,大概长得像这样:

或是这样:

对比一下sw26010,只需要这样,一块插件板上有8个节点:

然后这样:

得益于SW26010的超低功耗,大幅度降低了散热压力,一个小小的机箱塞进了256个计算节点。。。。同体积秒杀
intel。不要小看体积因素,更小的体积意味着可以用更快的总线和更低的成本将所有节点连接起来。而SW26010的节点轻松用PCI-E 3.0就连起来了,又便宜又快,喷总线瓶颈的可以省省了,天河二号用的自制TH-Express-2连接计算节点,使用PCI-E 2.0连接,根据资料显示速度是6.36GB/s,延迟是85us;而SW26010的计算节点连接性能高达12GB/s,延迟只有区区的1us,性能远超
intel方案的天河二号。然后这样一个小小的机柜,居然塞进了8机箱,像这样:
 下面说说超算闲置问题 针对此某HPC从业者这样回答
下面说说超算闲置问题 针对此某HPC从业者这样回答1.中国无论天河-1还是天河-2现在都是满负荷运转,根本没有闲置问题,天河1不说了,现在用得排队,天河2的国防科大自己想
测试下节点都经常没资源,所谓天河-2上利用效率不高也是相对于去目的的,把资源满负荷当然容易,以前跟袁学峰教授合作过,这么说吧,人家所谓利用不充分是说重大科研课题放在天河-2上的没他们期望的比例高,至于金融类动漫类低层次的应用,人家根本没把它们当正经应用(这类应用由于门槛低,并行度高,很容易占用大量计算资源),国防科大和广州天河的袁教授期望的是天河-2在国家重大专项等高层次应用上更多做出贡献,比如核物理,流体力学等代表超算顶尖水平的应用更多(这也是天河-3继续获得国家拨款的主要依据,国家一点都不傻),这当然有一定难度,因为天河-2是异构计算机,想充分利用这些资源,代码几乎都得重写,实际上,在美国TITAN上由于用了
GPU, 这类应用推进的也不怎么样。
2.以我在HPC工作接触的情况来看,江南所这个超算完全不用担心上述问题,因为江南所是军方背景,他们搞得计算机一个主要应用就是核物理仿真,中国在核物理仿真方面几乎全部代码都是自主搞得,而且很多代码都是针对江南所的计算硬件专门设计的,编译器加速库等生态系统一应俱全,因此这些在天河-2上遇到的问题,反而在神威上可能不是太大问题,一个例子就是神威超算刚上线,一个核物理仿真在神威上就取得了40P的惊人效率,并且有三个应用已经入围超算应用国际大奖评选了(效率3占到理论峰值多30%的超算应用是惊人的,实际上写过程序的都知道,别说超算,即便多核计算机,一般的应用能达到系统浮点峰值30%都是挺不错了)。
当然相应的,神威上部署民用应用,比如金融/动漫渲染之类低层次应用,反而难度会大一些,基本上代码得重写或者大改,但是对这种层次的超算,这些低水平应用本来就不是重点。
对很多核物理和流体,计算电磁学等高端计算来讲,现在超算不是能力太强,是太弱,因此只能千方百计地降低计算复杂度+各种简化,实际上即便是天河-2,做流体的直接数值模拟,也根本达不到可用的尺度!
以超算速率做为面积比重,分国家做出来的图,黄色部分为中国,红色是美国,然后是其它国家。
上榜的超算具体分布如下
欧洲共有105台超算上榜(比2015年11月的107台少2台),总体数量下降,远逊于亚洲国家。亚洲国家的超算高达218台,雄霸榜单,比上次的173台有了显著的增长。德国的超算数量在欧洲居冠,共有26台,法国以18台紧随其后,英国有12台。亚洲方面,日本以29台位于中国之后(比2015年的37台有显著下降)。
克雷系继续独领风骚,在所有的超算运算性能中占据19.9%的份额(比上次的25%有所下滑)。中国国家并行计算机工程中心仅凭借一台神威太湖之光在性能上名列第二,占16.4%。IBM则获得季军,占10.7%,比六个月前的14.9%下降不少。惠普占12.9%,比半年前的14.2%略微下滑。.
1.所有上榜超算的性能共计达566.7 pflop/s,而半年前为420 pflop/s,一年前则为363 pflop/s。性能提升的同时,涨幅较以往明显放缓。
2.共有95台超算的性能超过一亿亿次每秒,半年前仅有81台。
3.英特尔处理器仍占有绝对多数份额——在全球超算500强中,有455台超算采用该公司芯片,比重高达91%。IBM处理器的比重从半年前的26台降至如今的23台。13台超算采用AMD皓龙系列(占2.6%),不及半年前的4.2%。
4.惠普公司的产品最多,为127台(占25.4%),联想紧随其后,有84台。克雷则有60台,不及半年前的69台。半年前上榜的惠普公司产品为155台,而IBM本期上榜超算为38台,名列第五。
5.共用93台上榜超算采用了加速器或协处理器技术,比半年前的104台有所下滑。其中67台采用NVIDIA芯片,26台采用英特尔至强Phi技术,3台采用ATI Radeon,还有两台采用PEZY技术。3台超算同时采用NVIDIA和至强Phi加速器或协处理器。每台超算平均采用7.6万颗加速核心。
6.上榜门槛提高至LINPACK测试的285.9 tflop/s(每秒285.9万亿次运算——MIKADO译注),半年前的门槛则是206.3 tflop/s(每秒206.3万亿次运算——MIKADO译注)。 本次榜单的最后一名可排在上次榜单的第351位。
7.本榜单最后一名的性能增幅继续低于之前6年的增长水平,现在这一趋势得到进一步加强。 从1994年至2008年,增幅为平均每年90%,但2008年以后的增幅仅为平均每年55%。
国产超算发展史90年代初,为了彻底打破国外对高性能计算机的垄断,国家派出一支年轻精干的科研小分队,远赴美国硅谷去进行曙光一号的研究。当时的科学计算所所长李国杰在黑板上写下了“人生能有几回搏”七个大字,斩钉截铁的对几个年轻人说:“派你们去,就相信你们一定能把机器给造出来!” 在每天工作十五、六个小时,长达11个月的封闭式研究后,科研小分队成功设计出曙光一号核心部分。
在曙光一号的研发过程中,一些国外公司和国内买办对曙光一号研究小组的领头人李国杰院士说,“把钱给我,我给你造出来不就完了”。但李国杰院士坚持认为,高性能计算的核心技术必须掌握在中国人手中,这是一丝一毫都不能让步的,不仅要做整机研制,包括存储器在内的配件都要自己做。
1.1993年,中国一台高性能计算机曙光一号并行机终于研制成功。曙光一号的战略效应可以说是立竿见影:就在这台高性能计算机诞生的第三天,美国便宣布解除10亿次计算机对中国的禁运!成功打破了国外IT巨头对我国信息技术的垄断,推动信息产业走上了自主发展的道路。
2.1995年,在只有十余名研究员及500万元经费的情况下,中国成功研发出曙光1000大规模并行计算机。曙光1000在整体技术上居中国之首,并达到了20世纪90年代前期的国际先进水平,其运行速度的峰值达到了每秒25亿次,在当时我国大规模科学工程计算中发挥了重大作用。曙光1000也荣获了1996年中国科学院科技进步特等奖和1997年国家科学技术进步一等奖。
3.1998年,曙光2000问世,总体水平达到了90年代同期国际先进水平,有些方面如机群操作系统、集成化并行编程环境和服务器聚集软件等已处于国际领先水平。
4.2001年,曙光3000诞生,标志着我国超算产品正在走向成熟,能兼顾大规模科学计算、事物处理和网络信息服务,已然是国民经济信息化建设的重大装备。
5.2004年,曙光公司研发出4000A,成为国内首台每秒运算超过10万亿次的超级计算机,并代表中国首次进入全球超级计算机TOP 500排行榜,位列第十位。
6.2008年,曙光5000降生,曙光5000的系统峰值运算速度达到每秒230万亿次浮点运算,使中国成为继美国之后第二个能制造和应用超百万亿次商用高性能计算机的国家,也表明我国生产、应用、维护高性能计算机的能力达到世界先进水平。
7.2009年,作为第一台国产千万亿次超级计算机的天河一号在湖南长沙亮相。天河一号超级计算机性能为每秒1206万亿次的峰值速度,Linpack实测性能为每秒563.1万亿次,强劲的性能使天河一号位列中国超级计算机前100强之首,也使中国成为继美国之后世界上第二个能够自主研制千万亿次超级计算机的国家。2010年,国防科大对天河1号进行了升级,天河1A的实测运算能力从天河1号的每秒563.1万亿次,提升至2507万亿次,成为当时世界上最快的超级计算机。
8.2010年,曙光6000问世,曙光6000以实测每秒达1271万亿次的Linpack峰值速度,在2010年第35届全球超级计算机500强排名中名列第二。
9.2012年,神威蓝光超级计算机投入使用。该超算使用了8704片申威1600,搭载神威睿思操作系统,虽然超算绝对性能并不高,但却是中国在“市场换技术”之后,首次实现了超算CPU和操作系统的全部国产化。神威蓝光超算峰值计算性能为每秒一千万亿次,持续性能为每秒796万亿次,性能功耗比超过741MFlops/W(百万次浮点运算/秒•瓦),LINPACK效率为74%。
10.2013年,国防科大成功研制出天河2号,其高达55PFlops的性能使其傲视群雄,六度蝉联TOP500排行榜首位。虽然在计算节点上使用的是美国Intel的CPU,但天河2号也使用了4096片飞腾1500,用于高速互联网络系统。
如果说天河2号、曙光6000、天河1号等超算使用了国外CPU是白璧微瑕,那么,本次发布的新超算“神威太湖之光”则实现了CPU、操作系统、高速互联网络等核心软硬件的全面国产化——其CPU申威26010由260个核心构成,双精浮点峰值高达3TFlops,完全追平了Intel最好的超算芯片。
11.2016年6月20日,全球超级计算机500强榜单公布,使用中国自主芯片制造的“神威太湖之光”取代“天河二号”登上榜首,成为世界首台运算速度超过10亿亿次的超级计算机,其每秒浮点运算峰值达到12.54亿亿次,持续运算能力达每秒9.3亿亿次,运算速度是使用intel芯片天河二号的三倍。